网站策划怎么写查网站流量的网址
在深度学习的发展中,注意力机制的引入曾被誉为一次划时代的技术飞跃。无论是在自然语言处理领域产生Transformer架构,还是在图像识别、语音识别和推荐系统等多个方向取得显著成效,注意力机制的价值似乎毋庸置疑。然而,在一些实际应用场景中,研究人员和工程师却发现:在传统神经网络中引入注意力机制后,模型的预测精度不仅没有提升,反而下降了。这是一种背离常识的现象,也成为研究与实践中的棘手难题。
1. 注意力机制的本质是什么?
注意力机制(Attention Mechanism)最早源于对人类视觉聚焦过程的模拟。当我们观察一张图像时,目光不会均匀地扫视全图,而是有意识地聚焦于关键信息区域。神经网络中的注意力机制,正是试图对输入特征分配不同的权重,使模型更关注有用信息。
形式上,注意力机制可以抽象为一种加权求和操作: 给定查询向量 ,键向量集合 ,值向量集合 ,注意力机制输出为:
其中, 是通过 softmax 函数计算的注意力权重,衡量 与 的相关性。
理论上,这种机制可以增强模型对长距离依赖、关键特征的感知能力。然而,注意力机制的引入并不总能带来性能的提升,尤其在结构复杂、数据分布变化较大或训练策略不当时,容易适得其反。
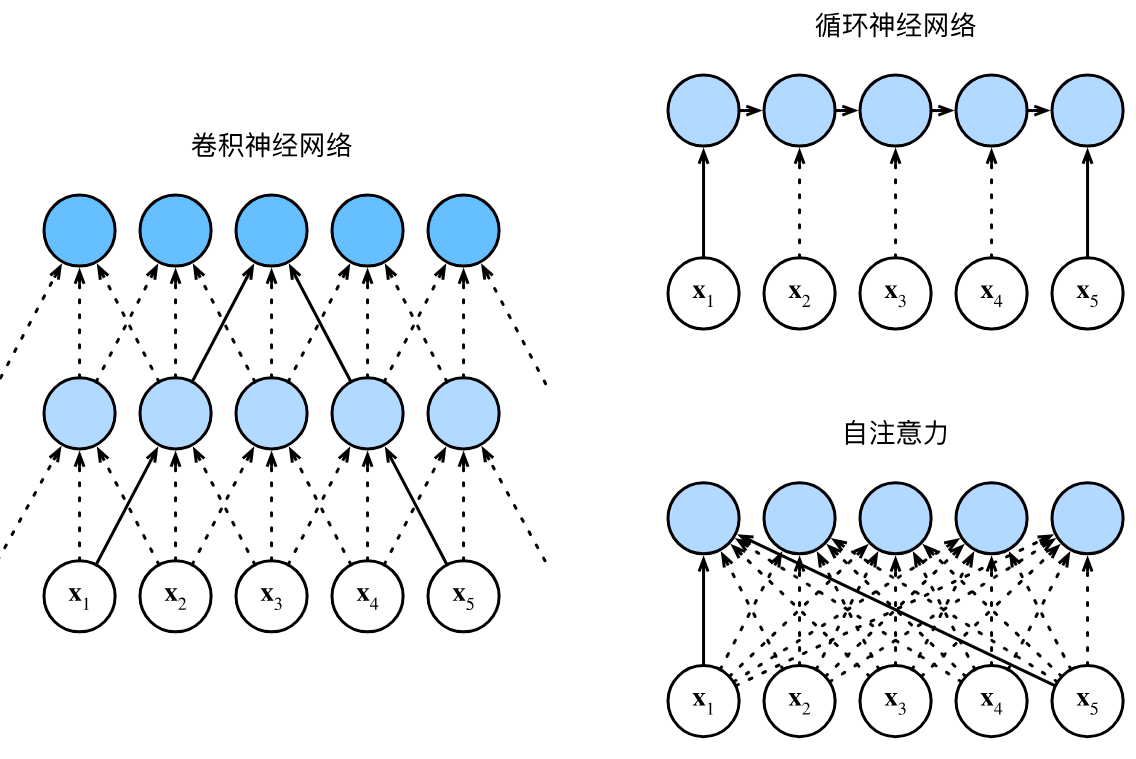
2. 为什么加入注意力机制反而精度下降?
2.1 参数爆炸与过拟合风险增加
注意力机制通常需要引入额外的参数,如查询、键、值向量的线性变换权重。以多头注意力(Multi-Head Attention)为例,它会在每个头上复制一套注意力参数,导致参数量成倍增长。
风险:
-
在小数据集或训练数据分布不稳定的场景下,大量新参数容易导致模型陷入过拟合;
-
模型学习到的注意力权重可能过度贴合训练样本,泛化能力变差。
示例:某些小型分类任务(如CIFAR-10)中,ResNet加入Self-Attention层后精度不升反降。
2.2 特征稀释与信息干扰
注意力机制对所有输入特征进行加权融合,有可能掩盖关键特征,使得有用信息被噪声干扰。
解释:
-
如果注意力权重分布过于均匀(即 softmax 输出近似平坦),则各个特征之间的差异性会被抹平;
-
如果注意力机制学习错误(例如关注无关区域),将干扰后续层的判断。
原因可能是:
-
训练初期参数未收敛,attention map 随机波动;
-
查询向量的表示能力不足,导致注意力误导。
2.3 优化过程不稳定
注意力机制中的 softmax 操作可能带来梯度爆炸或梯度消失等问题。
原理:
-
在 dot-product attention 中,如果向量维度很高,点积结果数值极大,softmax 后趋向于 one-hot 分布,造成梯度传播不稳定;
-
Transformer 中通过缩放因子 缓解这一问题,但在不使用此缩放的注意力模块中,仍容易出现梯度爆炸。
2.4 与原有架构不兼容
在现有神经网络结构中强行嵌入注意力模块,可能破坏原有的信息流路径。
常见问题:
-
残差连接与注意力模块冲突,造成梯度反向传播通路中断;
-
卷积网络中直接替换卷积层为注意力层,缺失空间局部性建模能力;
-
注意力层过深堆叠,使得模型学习的表示变得冗余、难以提炼核心特征。
2.5 数据与任务特性不匹配
注意力机制并非在所有任务中都有助益。对某些依赖强先验结构的任务,如图像分割、实体识别等,过度依赖注意力可能导致模型偏离任务本质。
例如:
-
对于语音识别这类时间顺序严格的重要任务,使用全局注意力可能混淆前后文关系;
-
对于图像分类任务,注意力有时会关注边缘背景而非核心物体。
3. 理论视角:从表示学习看注意力机制的局限性
3.1 表示容量膨胀
模型的表达能力虽然增强了,但可解释性下降,训练难度提升。信息冗余可能掩盖核心特征,增加模型泛化误差。
3.2 信息路径混淆
注意力机制本质是将所有信息路径均连通,破坏了原始结构的局部归纳偏置(如卷积中的局部感受野)。
4. 实验与案例分析
我们选取几个具体案例进行说明:
4.1 Vision Transformer vs CNN
在小数据集上,ViT 由于缺乏卷积的归纳偏置,表现不如 ResNet。只有在大规模预训练+微调的情境下,ViT 才能展现其优势。
结论:注意力机制需要足够数据与合适架构支持。
4.2 加入SE模块的MobileNetV3在某些任务上退化
Squeeze-and-Excitation模块通过通道注意力进行加权,然而在某些轻量级模型中,引入SE模块后性能下降。可能原因是:
-
网络被迫关注过细的通道特征;
-
新增参数破坏了原有高效性。
5. 如何正确使用注意力机制?
5.1 匹配任务需求
-
对依赖长距离依赖的任务(如NLP)使用全局注意力;
-
对结构性强的任务(如CV)可用局部注意力或卷积注意力结合;
-
对轻量模型避免大规模注意力模块。
5.2 合理架构设计
-
注意力与残差、归一化等模块协同使用;
-
使用多头注意力提升稳定性;
-
加入结构归纳偏置,如位置编码、稀疏连接等。
5.3 正确初始化与训练策略
-
使用预训练模型;
-
加入正则化手段如Dropout防止过拟合;
-
采用 LayerNorm 稳定训练过程。
5.4 模块可视化与诊断
通过 Attention Map 可视化工具,检查模型关注区域,及时发现模型关注偏移或异常。
6. 未来研究方向
6.1 动态注意力机制
引入条件计算机制,根据输入样本动态激活部分注意力头,提升效率和性能。
6.2 注意力机制的可解释性研究
发展可解释的注意力图生成机制,增强模型信任度和调试能力。
6.3 与其他机制结合
融合图神经网络、神经模糊逻辑系统、结构建模等手段,增强注意力机制的表示能力与泛化能力。
结语:不是所有的注意力都能提高性能
“加注意力一定更好”是一种误区。正如焦点太多反而无法专注,神经网络在特征选择过程中也需保持信息的选择性与判别性。本文从多个维度剖析了注意力机制引起精度下降的可能原因,希望为模型构建者提供深刻的启示:技术的进步不是盲目堆叠,而是精巧设计与适配的艺术。