动漫网站模板代码优化
目录
前言
一、Selenium的简介和学习准备
二、Selenium基本使用
三、声明浏览器对象
四、访问页面
五、查找节点
5.1 单个节点
5.2 多个节点
六、节点交互
七、动作链
八、执行JavaScript
前言
本专栏之前的内容,我们讲了怎么分析和抓取Ajax,这其实是JavaScript动态渲染页面的一种情况。利用requests或者urllib,直接对Ajax进行分析,也能实现数据爬取。
不过,JavaScript动态渲染页面可不只有Ajax这一种。就说中国青年网(网址是[http://news.youth.cn/gn/](http://news.youth.cn/gn/)),它的分页部分是用JavaScript生成的,不是原本的HTML代码,而且里面也没有Ajax请求。再看看ECharts的官方实例(网址是[http://echarts.baidu.com/demo.html](http://echarts.baidu.com/demo.html)),页面上的图形都是通过JavaScript计算后生成的。还有淘宝这类页面,虽然数据是通过Ajax获取的,但是它的Ajax接口有好多加密参数,我们很难直接找出规律,也就没办法光靠分析Ajax来抓取数据。
要解决这些问题,可以用模拟浏览器运行的办法。这样一来,浏览器里显示的页面是什么样,我们抓取到的源码内容就是什么样,也就是达到“所见即所得”,能实现“可见即可爬”。这么做,我们就不用去管网页内部JavaScript用的页面渲染算法,也不用操心网页后台Ajax接口具体的参数设置了。
Python有不少能模拟浏览器运行的库,像Selenium、Splash、PyV8、Ghost等等。接下来,我们主要讲讲Selenium和Splash的使用方法。学会了它们,抓取动态渲染页面就没那么难了。这一节我们开始进入新版Selenium 4的使用学习,旧版的会稍微提到。
一、Selenium的简介和学习准备
Selenium是一个自动化测试工具,借助它可以操控浏览器去执行一些特定的操作,比如点击按钮、下拉页面等。而且,它还能获取到浏览器当前显示页面的源代码,从而实现“可见即可爬”,这对于抓取那些由JavaScript动态渲染的页面来说非常有用。在这一节内容里,我们就一起来感受一下Selenium的强大之处。
这一节我们会以Chrome浏览器为例,详细讲解Selenium的具体使用方法。在正式开始操作之前,大家要通过正确运行pip命令来安装Python的Selenium库。另外,一定要保证已经正确安装了Chrome浏览器,并且也要安装上 ChromeDriver 到 Chrome 同级目录下,并配置好环境变量,ChromeDriver如何安装请自行网上查找教程。下面我们都是在windows上进行实操。
selenium学习文档如下:
(1)入门指南和api使用:
( https://www.selenium.dev/zh-cn/documentation/webdriver/getting_started/ )
(2)官方文档(最权威):
包含了最新的 API 文档和使用指南
- https://www.selenium.dev/documentation/
- https://www.selenium.dev/selenium/docs/api/py/
(3)Python Selenium 包文档:
这是专门针对 Python 的 Selenium 文档,比较容易理解
https://selenium-python.readthedocs.io/
二、Selenium基本使用
当把前期的准备工作都妥善完成后,我们首先来初步认识一下Selenium所拥有的各项功能。下面为大家展示一个具体的示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options# 配置Chrome选项
chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,不显示浏览器窗口
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
# 添加实验性选项,防止浏览器自动关闭
chrome_options.add_experimental_option("detach", True)# 创建Chrome浏览器实例
browser = webdriver.Chrome(options=chrome_options)try:browser.get('https://www.baidu.com')# 使用新的查找元素方法input_element = browser.find_element(By.ID, 'kw')input_element.send_keys('Python')input_element.send_keys(Keys.ENTER)wait = WebDriverWait(browser, 10)wait.until(EC.presence_of_element_located((By.ID, 'content_left')))print(browser.current_url)print(browser.get_cookies())print(browser.page_source)# 保持浏览器打开,直到用户手动关闭print("\n浏览器将保持打开状态。要关闭浏览器,请按回车键...")input() # 等待用户输入
except Exception as e:print(f"发生错误: {e}")
finally:# 如果用户按了回车,则关闭浏览器if input("是否关闭浏览器?(y/n): ").lower() == 'y':browser.quit()else:print("浏览器将保持打开状态。请手动关闭浏览器窗口。")执行完上面的代码以后,会自动弹出一个Chrome浏览器窗口。这个浏览器会先跳转到百度的首页,然后在搜索框里输入“Python”这个关键词,输入完成后就会跳转到相应的搜索结果页面了,具体页面显示的样子就如同下面的图片所示。
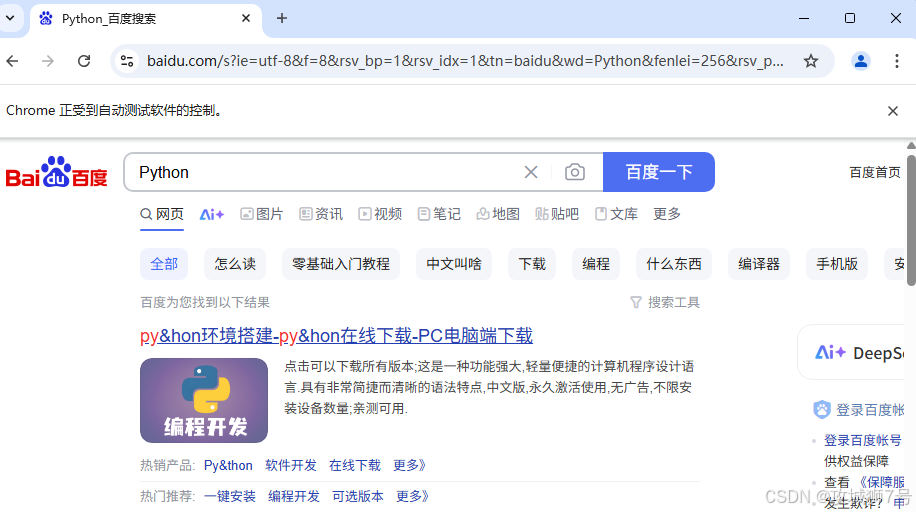
在这个时候,控制台会把我们获取到的当前网页的URL地址、Cookies信息以及网页的源代码都输出显示出来,这些输出的内容可都是浏览器里实实在在存在的真实信息。
从这里就能看出来,要是用Selenium来操控浏览器去加载网页,我们可以直接拿到经过JavaScript渲染之后的网页内容,根本不用去担心网页所使用的加密系统是怎么回事。那接下来呢,我们就再进一步详细地了解一下Selenium具体的使用方法吧。
三、声明浏览器对象
Selenium能够适配多种不同的浏览器。像常见的桌面端浏览器,比如Chrome、Firefox、Edge这些它都支持;在手机端,像Android系统、BlackBerry系统所使用的浏览器也在其支持范围内。另外,还有无界面浏览器PhantomJS,Selenium同样可以支持。要是我们想使用Selenium,可通过下面这些方式来完成初始化操作:
from selenium import webdriverbrowser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()通过上面给出的代码,我们成功地对浏览器对象进行了初始化设置,并把初始化后的浏览器对象赋值给了名为browser的变量。在接下来的操作中,我们只要调用这个browser变量所代表的对象,就能够让它去执行各种各样的动作,从而实现对浏览器实际操作的模拟。
四、访问页面
利用Selenium来访问网页特别简单,只要调用它的get()方法就行,并且把想要访问的网页链接URL当作参数传进去就可以了。就好比说,我们要用get()方法来访问淘宝网页,然后把页面的源代码打印出来,具体的代码如下所示:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()当我们运行上述代码后,Chrome浏览器会自行弹出并开始访问淘宝网站。紧接着,控制台就会把淘宝页面的源代码显示出来。等到这些操作完成后,浏览器也会随之关闭。
仅仅依靠这简短的几行代码,我们就成功地做到了驱动浏览器去访问网页,并且还获取到了网页的源代码,整个过程操作起来真的非常方便快捷。
五、查找节点
Selenium可以操控浏览器完成各种复杂的操作,像填充表单、模拟点击等。要是我们想往某个输入框里输入文字,得先知道这个输入框在网页上的位置。为了解决这个问题,Selenium提供了一堆查找节点的方法,用这些方法,我们就能找到目标节点,之后就能执行相关操作或者提取需要的信息了。
5.1 单个节点
就拿从淘宝页面提取搜索框节点这件事来说吧,我们第一步要做的就是查看淘宝页面的源代码,具体情况就像下面的图片展示的那样。
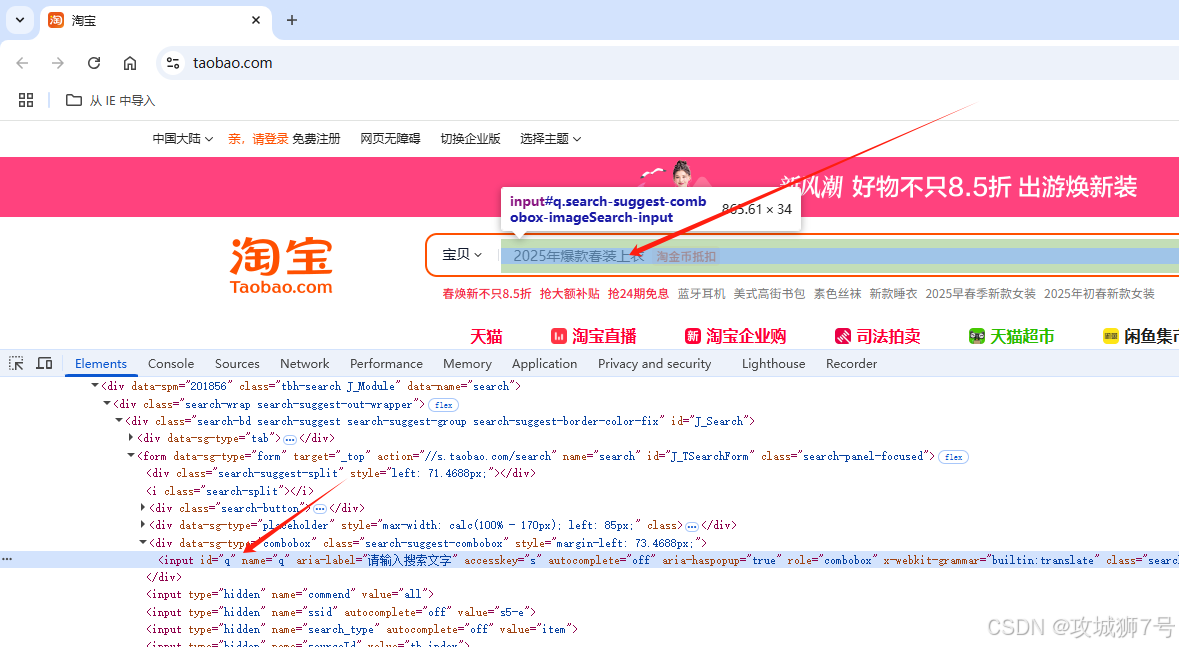
从这张图上我们能够看到,这个搜索框的id和name属性值都是“q”,除此之外,它还有很多其他的属性。根据这些特点,我们有好几种办法可以获取到这个节点。比如说,旧版本利用find_element_by_name()方法,通过输入name的值就能够获取到对应的节点;而find_element_by_id()方法呢,则是按照id的值来获取节点。另外,我们还可以借助XPath、CSS选择器这些方式来确定节点的位置。然而我们要用新版的api-find_element完成,下面我们就通过代码来实际展示一下这些方法是怎么操作的:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options# 配置Chrome选项
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) # 保持浏览器打开browser = webdriver.Chrome(options=chrome_options)
browser.get('https://www.taobao.com')# 旧版本的元素查找方法(已不支持)
# input_first = browser.find_element_by_id('q')
# input_second = browser.find_element_by_css_selector('#q')
# input_third = browser.find_element_by_xpath('//*[@id="q"]')# 使用新版本的元素查找方法
input_first = browser.find_element(By.ID, 'q')
input_second = browser.find_element(By.CSS_SELECTOR, '#q')
input_third = browser.find_element(By.XPATH, '//*[@id="q"]')print(input_first, input_second, input_third)# 不关闭浏览器
# browser.close()在上述的代码里,我们依次运用了依据ID、CSS选择器以及XPath这三种不同的方法去获取输入框的节点。从运行的结果来看,这三种方式所返回的结果是一模一样的。具体的输出内容如下所示:
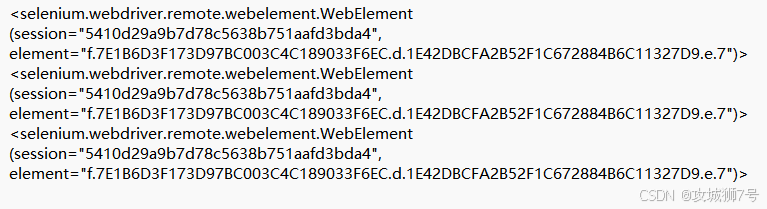
可以看到,这三个节点均为WebElement类型,且完全相同。
以下是获取单个节点的所有方法列表:
旧版本(Selenium 3及之前) → 新版本(Selenium 4及之后):
1. `find_element_by_id()` → `find_element(By.ID, ...)`
2. `find_element_by_name()` → `find_element(By.NAME, ...)`
3. `find_element_by_xpath()` → `find_element(By.XPATH, ...)`
4. `find_element_by_link_text()` → `find_element(By.LINK_TEXT, ...)`
5. `find_element_by_partial_link_text()` → `find_element(By.PARTIAL_LINK_TEXT, ...)`
6. `find_element_by_tag_name()` → `find_element(By.TAG_NAME, ...)`
7. `find_element_by_class_name()` → `find_element(By.CLASS_NAME, ...)`
8. `find_element_by_css_selector()` → `find_element(By.CSS_SELECTOR, ...)`
主要变化:
1. 所有方法统一使用 `find_element()` 函数
2. 使用 `By` 类的常量来指定查找方式
3. 参数分为两部分:查找方式和查找值
另外还要注意:
- 查找单个元素用 `find_element()`
- 查找多个元素用 `find_elements()`(返回列表)
- 所有的 `By` 常量都是大写的
- 新版本的写法更统一,更容易记忆
通用方法find_element(),该方法需要传入两个参数:查找方式By和对应的值。实际上,它是find_element_by_id()等方法的通用版本,例如find_element_by_id(id)与find_element(By.ID, id)的功能完全一致,二者返回的结果也相同。通过代码演示如下:
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()这种查找方式在功能上与上述列举的查找函数相同,但参数设置更为灵活。
5.2 多个节点
要是在网页里,我们要查找的目标就只有一个,那么使用find_element()方法就行。但要是有多个节点都符合我们设定的查找条件,这时再用find_element()方法,就只能获取到这些符合条件的节点里的第一个。如果我们想把所有满足条件的节点都找出来,那就得用find_elements()方法。要注意哦,这个方法的名称里,element后面多了个“s”,使用的时候一定要区分清楚。
打个比方,要是我们想找出淘宝左侧导航栏里的所有条目,你可以参考下面这张图。
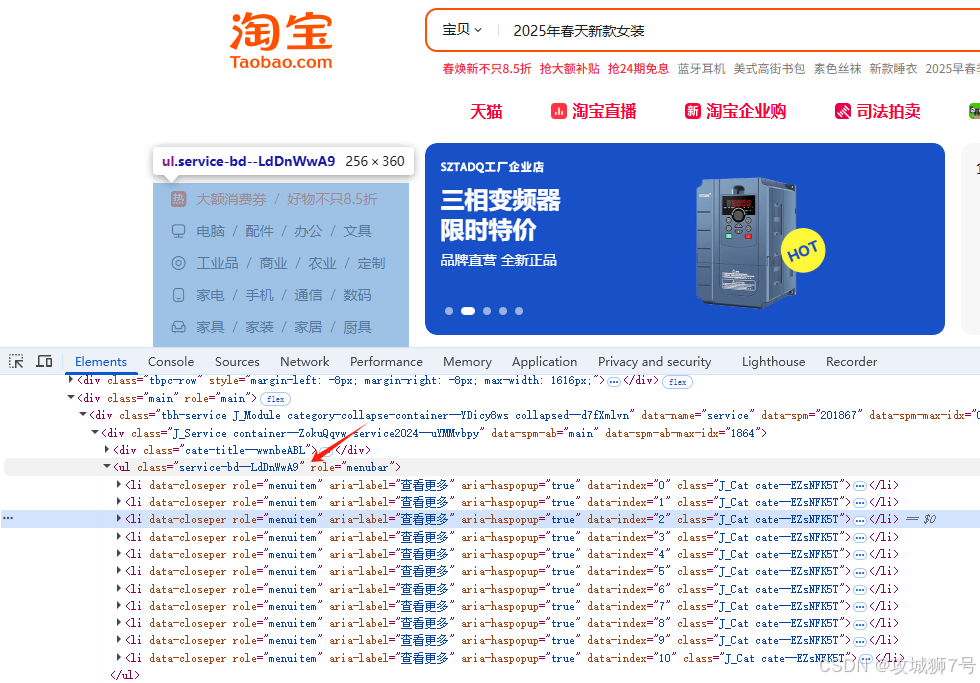
实现代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')
# lis = browser.find_elements_by_css_selector('.service-bd li') # 旧版本写法
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd--LdDnWwA9 li') # 新版本写法
print(lis)
browser.close()运行上述代码后,输出结果如下:
从输出结果能够发现,获取到的内容属于列表类型,并且列表里的每个节点都是WebElement类型。
这就意味着,使用find_element()方法只能获取到符合匹配条件的第一个节点,其结果是WebElement类型;而使用find_elements()方法,返回的结果是列表类型,列表中的每个节点同样是WebElement类型。
下面为你介绍获取多个节点的所有方法:
# 1. ID查找
旧版本: browser.find_elements_by_id('myId')
新版本: browser.find_elements(By.ID, 'myId')# 2. NAME查找
旧版本: browser.find_elements_by_name('myName')
新版本: browser.find_elements(By.NAME, 'myName')# 3. XPATH查找
旧版本: browser.find_elements_by_xpath('//div[@class="myClass"]')
新版本: browser.find_elements(By.XPATH, '//div[@class="myClass"]')# 4. 链接文本查找
旧版本: browser.find_elements_by_link_text('点击这里')
新版本: browser.find_elements(By.LINK_TEXT, '点击这里')# 5. 部分链接文本查找
旧版本: browser.find_elements_by_partial_link_text('点击')
新版本: browser.find_elements(By.PARTIAL_LINK_TEXT, '点击')# 6. 标签名查找
旧版本: browser.find_elements_by_tag_name('div')
新版本: browser.find_elements(By.TAG_NAME, 'div')# 7. 类名查找
旧版本: browser.find_elements_by_class_name('myClass')
新版本: browser.find_elements(By.CLASS_NAME, 'myClass')# 8. CSS选择器查找
旧版本: browser.find_elements_by_css_selector('.myClass > div')
新版本: browser.find_elements(By.CSS_SELECTOR, '.myClass > div')六、节点交互
Selenium可以操控浏览器开展一系列操作,以此模拟浏览器在实际中的行为。一些常见的操作方法有:利用send_keys方法往输入框里输入文字,使用clear方法清空输入框里已有的内容,通过click方法点击页面上的按钮等等。下面给出一个示例来进行说明:
from selenium import webdriver
from selenium.webdriver.common.by import By
import timebrowser = webdriver.Chrome()
browser.get('https://www.taobao.com')# 旧版API
# input = browser.find_element_by_id('q')
# 新版API
input = browser.find_element(By.ID, 'q')input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')# 旧版API
# button = browser.find_element_by_class_name('btn-search')
# 新版API
button = browser.find_element(By.CLASS_NAME, 'btn-search')button.click()
在这段代码里,第一步是让浏览器启动并进入淘宝页面。接着,运用新版 find_element 函数,成功定位到页面上的搜索框节点。随后,借助send_keys()函数,往搜索框里输入了“iPhone”。稍作停顿,等待1秒钟后,使用clear()函数把搜索框里刚输入的内容清空。紧接着,再次调用send_keys()函数,这次输入的是“iPad”。之后,利用新版 find_element 函数,找到了搜索按钮对应的节点,最后通过click()函数执行点击操作,完成了搜索。
利用上述这些步骤,我们实现了与页面中常见节点的交互操作。要是你还想了解更多这类交互操作的方法,可以查阅官方文档中有关交互动作的内容,链接为:(http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement) 。
七、动作链
在之前的例子里,大部分交互操作都是围绕特定节点展开的。就像对输入框进行输入内容和清空内容的操作,对按钮进行点击操作。不过,还有一些操作并不针对特定的某个节点,像鼠标拖曳、按下键盘按键等,这类操作可以借助动作链来达成。
下面以节点拖曳操作为例,也就是把某个节点从一个位置拖到另一个位置,代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
import timebrowser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)# 等待iframe加载
time.sleep(2)
browser.switch_to.frame('iframeResult')# 等待元素加载
time.sleep(2)# 新版API
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')# 执行拖拽操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()# 等待alert出现
time.sleep(1)# 处理alert
alert = browser.switch_to.alert
print(alert.text) # 应该输出 "dropped"
alert.accept()# 保持浏览器打开
input("按回车键关闭浏览器...")
在上述代码当中,最开始的操作是打开那个带有拖曳示例的网页。随后,运用switch_to.frame()方法,切换进入到指定的iframe框架里面。紧接着,分别把需要进行拖曳的源节点以及目标节点选取出来,同时声明一个ActionChains对象,并将其赋值给actions这个变量。
而后,调用actions变量所对应的drag_and_drop()方法,以此来设定拖曳的动作,再通过perform()方法来执行这一动作,如此便成功完成了对节点的拖曳操作。在进行拖曳操作之前和之后,页面所呈现出来的效果分别如下面的两张图片所示。
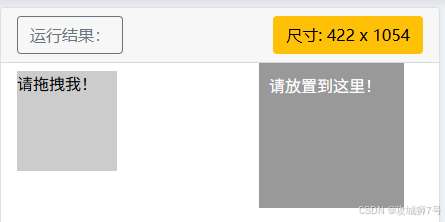
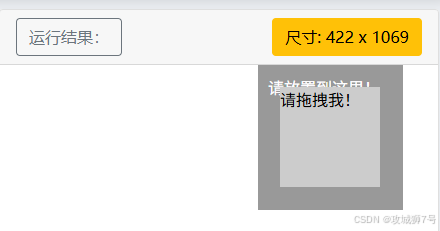
注意:运行的时候可能需要等待一会看效果
要是还想了解更多关于动作链的操作方法,可以查阅官方文档里有关动作链的相关内容,具体的链接是 (http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains)。
八、执行JavaScript
在使用Selenium开展自动化测试工作时,有时会遇到一些Selenium API并未直接支持的操作,像下拉网页进度条这种需求就难以直接借助Selenium API完成。不过,我们可以采用直接模拟运行JavaScript代码的方式来实现这类操作。在这种场景下,能够使用`execute_script()`方法。下面给出示例代码,通过它可以清晰地看到如何运用该方法达成特定的操作目的:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')# 等待用户按回车键
input("按回车键关闭浏览器...")前面已经说过,利用`page_source`属性能够获取网页的源代码,之后可以使用正则表达式、Beautiful Soup、pyquery等解析库来提取我们需要的信息。
不过,因为Selenium已经提供了选择节点的方法,而且这些方法返回的是WebElement类型的对象,所以Selenium肯定也有直接提取节点属性、文本等信息的方法和属性。这样的话,我们就不用再通过解析源代码来获取信息了,操作会变得更加方便快捷。