学习日常网站建设作业软件开发工具
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

数据介绍
Tokenizer
分词器将单词从自然语言通过“词典”映射到0, 1, 36这样的数字,可以理解为数字就代表了单词在“词典”中的页码。 可以选择自己构造词表训练一个“词典”,代码可见./scripts/train_tokenizer.py(仅供学习参考,若非必要无需再自行训练,MiniMind已自带tokenizer)。
或者选择比较出名的开源大模型分词器, 正如同直接用新华/牛津词典的优点是token编码压缩率很好,缺点是页数太多,动辄数十万个词汇短语; 自己训练的分词器,优点是词表长度和内容随意控制,缺点是压缩率很低(例如"hello"也许会被拆分为"h e l l o" 五个独立的token),且生僻词难以覆盖。
“词典”的选择固然很重要,LLM的输出本质上是SoftMax到词典N个词的多分类问题,然后通过“词典”解码到自然语言。 因为MiniMind体积需要严格控制,为了避免模型头重脚轻(词嵌入embedding层参数在LLM占比太高),所以词表长度短短益善。
下面是常见的词表长度如下:
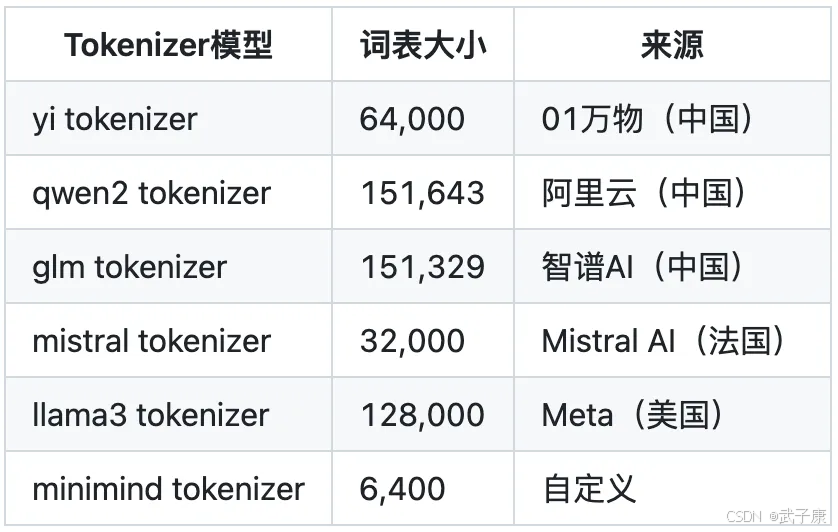
来自项目作者:
一些自言自语
尽管minimind_tokenizer长度很小,编解码效率弱于qwen2、glm等中文友好型分词器。
但minimind模型选择了自己训练的minimind_tokenizer作为分词器,以保持整体参数轻量,避免编码层和计算层占比失衡,头重脚轻,因为minimind的词表大小只有6400。
且minimind在实际测试中没有出现过生僻词汇解码失败的情况,效果良好。
由于自定义词表压缩长度到6400,使得LLM总参数量最低只有25.8M。
训练数据tokenizer_train.jsonl均来自于匠数大模型数据集,这部分数据相对次要,如需训练可以自由选择。
Pretrain数据
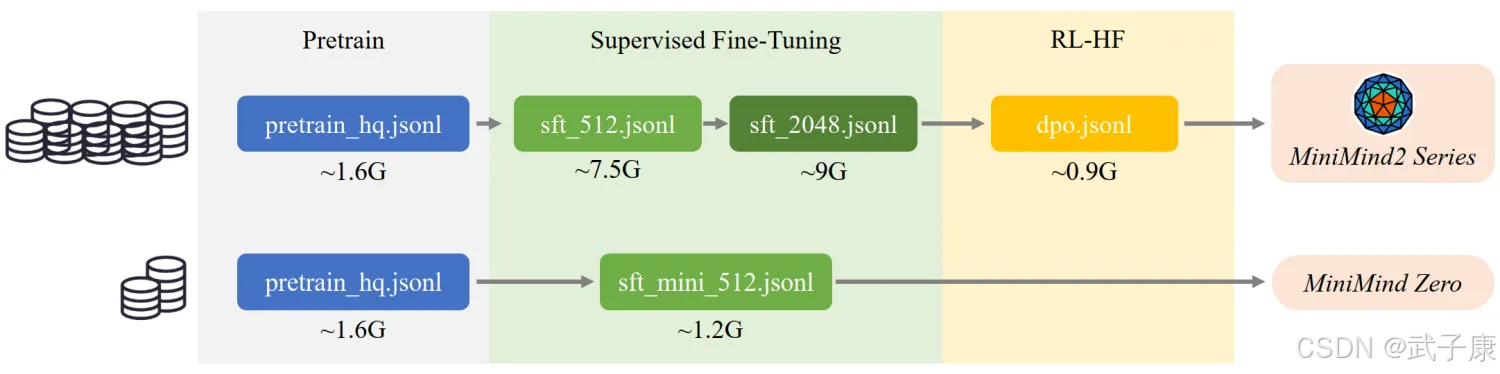
经历了MiniMind-V1的低质量预训练数据,导致模型胡言乱语的教训,2025-02-05 之后决定不再采用大规模无监督的数据集做预训练。 进而尝试把匠数大模型数据集的中文部分提取出来, 清洗出字符<512长度的大约1.6GB的语料直接拼接成预训练数据 pretrain_hq.jsonl,hq即为high quality(当然也还不算high,提升数据质量无止尽)。
文件pretrain_hq.jsonl 数据格式为:
{"text": "如何才能摆脱拖延症? 治愈拖延症并不容易,但以下建议可能有所帮助..."}
SFT数据
匠数大模型SFT数据集 “是一个完整、格式统一、安全的大模型训练和研究资源。 从网络上的公开数据源收集并整理了大量开源数据集,对其进行了格式统一,数据清洗, 包含10M条数据的中文数据集和包含2M条数据的英文数据集。” 以上是官方介绍,下载文件后的数据总量大约在4B tokens,肯定是适合作为中文大语言模型的SFT数据的。 但是官方提供的数据格式很乱,全部用来sft代价太大。 我将把官方数据集进行了二次清洗,把含有符号污染和噪声的条目去除;另外依然只保留了总长度<512 的内容,此阶段希望通过大量对话补充预训练阶段欠缺的知识。 导出文件为sft_512.jsonl(~7.5GB)。
Magpie-SFT数据集 收集了1M条来自Qwen2/2.5的高质量对话,我将这部分数据进一步清洗,把总长度<2048的部分导出为sft_2048.jsonl(9GB)。 长度<1024的部分导出为sft_1024.jsonl(~5.5GB),用大模型对话数据直接进行sft就属于“黑盒蒸馏”的范畴。
进一步清洗前两步sft的数据(只保留中文字符占比高的内容),筛选长度<512的对话,得到sft_mini_512.jsonl(~1.2GB)。
所有sft文件 sft_X.jsonl 数据格式均为
{"conversations": [{"role": "user", "content": "你好"},{"role": "assistant", "content": "你好!"},{"role": "user", "content": "再见"},{"role": "assistant", "content": "再见!"}]
}
RLHF数据
来自Magpie-DPO数据集 大约200k条偏好数据(均是英文)生成自Llama3.1-70B/8B,可以用于训练奖励模型,优化模型回复质量,使其更加符合人类偏好。 这里将数据总长度<3000的内容重组为dpo.jsonl(~0.9GB),包含chosen和rejected两个字段,chosen 为偏好的回复,rejected为拒绝的回复。
文件 dpo.jsonl 数据格式为:
{"chosen": [{"content": "Q", "role": "user"}, {"content": "good answer", "role": "assistant"}], "rejected": [{"content": "Q", "role": "user"}, {"content": "bad answer", "role": "assistant"}]
}
Reason数据集
不得不说2025年2月谁能火的过DeepSeek… 也激发了我对RL引导的推理模型的浓厚兴趣,目前已经用Qwen2.5复现了R1-Zero。 如果有时间+效果work(但99%基模能力不足)我会在之后更新MiniMind基于RL训练的推理模型而不是蒸馏模型。 时间有限,最快的低成本方案依然是直接蒸馏(黑盒方式)。 耐不住R1太火,短短几天就已经存在一些R1的蒸馏数据集R1-Llama-70B、R1-Distill-SFT、 Alpaca-Distill-R1、 deepseek_r1_zh等等,纯中文的数据可能比较少。 最终整合它们,导出文件为r1_mix_1024.jsonl,数据格式和sft_X.jsonl一致。
更多数据集
目前已经有HqWu-HITCS/Awesome-Chinese-LLM 在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,并持续更新这方面的最新进展。全面且专业,Respect!
数据集下载
MiniMind训练数据集 (ModelScope | HuggingFace)
无需全部clone,可单独下载所需的文件
将下载的数据集文件放到./dataset/目录下(✨为推荐的必须项)
./dataset/
├── dpo.jsonl (909MB)
├── lora_identity.jsonl (22.8KB)
├── lora_medical.jsonl (34MB)
├── pretrain_hq.jsonl (1.6GB, ✨)
├── r1_mix_1024.jsonl (340MB)
├── sft_1024.jsonl (5.6GB)
├── sft_2048.jsonl (9GB)
├── sft_512.jsonl (7.5GB)
├── sft_mini_512.jsonl (1.2GB, ✨)
└── tokenizer_train.jsonl (1GB)
各数据集简介:
● dpo.jsonl --RLHF阶段数据集
● lora_identity.jsonl --自我认知数据集(例如:你是谁?我是minimind…),推荐用于lora训练(亦可用于全参SFT,勿被名字局限)
● lora_medical.jsonl --医疗问答数据集,推荐用于lora训练(亦可用于全参SFT,勿被名字局限)
● pretrain_hq.jsonl✨ --预训练数据集,整合自jiangshu科技
● r1_mix_1024.jsonl --DeepSeek-R1-1.5B蒸馏数据,每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)
● sft_1024.jsonl --整合自Qwen2.5蒸馏数据(是sft_2048的子集),每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)
● sft_2048.jsonl --整合自Qwen2.5蒸馏数据,每条数据字符最大长度为2048(因此训练时设置max_seq_len=2048)
● sft_512.jsonl --整合自匠数科技SFT数据,每条数据字符最大长度为512(因此训练时设置max_seq_len=512)
● sft_mini_512.jsonl✨ --极简整合自匠数科技SFT数据+Qwen2.5蒸馏数据(用于快速训练Zero模型),每条数据字符最大长度为512(因此训练时设置max_seq_len=512)
● tokenizer_train.jsonl --均来自于匠数大模型数据集,这部分数据相对次要,(不推荐自己重复训练tokenizer,理由如上)如需自己训练tokenizer可以自由选择数据集。
整体结构如下: