南京网站制作公司怎么样湖南长沙最新疫情

近年来,社交媒体趋势分析逐渐成为品牌监控、市场洞察和消费者研究的必备工具。而当谈到全球趋势数据分析,很多人都会立即想到 Twitter趋势(逼近连美丽国的总统都喜欢在上面发表自己的看法- -!!!)。Twitter趋势,即Twitter提供的热门话题榜单,透过其中的关键词或话题标签(#tag),你可以快速了解当前全球用户关注的焦点。因此,分析这些数据,能够为市场营销、舆情监控、品牌竞争研究等提供基础信息。
但埋头获取趋势数据,并不像看起来那么简单。一旦让Twitter检测到异常采集行为,你的账号访问权限可能会被冻结。因此,我们需要采用Python结合海外代理IP,高效获取数据。
所以今天,我要分享的是:通过海外代理IP与Python的力量,如何一步步完成Twitter趋势数据的抓取和分析。
在开始前特别说明,我们此次内容是合法与合规的学习和技术探讨,获取和分析数据时,应严格遵守相关网站的服务协议与数据隐私法律。
一、为什么需要海外代理IP?
在进行社交数据采集时,你的关键是:稳定性与可用率。如果只有一台采集设备,想获取大量数据,往往会面临访问频率限制,但通过高质量的海外代理IP,你可以轻松解决这一难题。
1.使用海外代理IP有哪些好处?
-
完整性:获取特定地区的数据(如美国、印度或英国等国家的趋势话题)。
-
稳定性:避免因高并发请求导致本地IP被暂时限制。
-
精准性:确保收集的数据来源于目标区域,提高数据分析的有效性。
2.为什么是青果网络海外代理IP?
-
行业领先的技术架构:支持全球200+城市的精准IP定位,资源池覆盖2000万级以上纯净IP资源池,可无缝切换不同地区网络环境,满足跨境电商、市场调研等场景的地域模拟需求;
-
自研IP分池技术实现动态资源调度,使采集成功率比行业平均水平高出30%,支持大规模高并发场景的数据抓取、TikTok直播等高风控场景,避免因IP污染导致的封禁风险;
-
海外代理IP默认禁用中国大陆网络环境接入,从源头规避IP滥用风险,符合跨境业务合规要求,确保用户在使用过程中不会遭遇风控预警,降低风险。
-
成本优势显著,设有不限流量计费模式,相比传统按流量计费方案,有效规避了因流量超标而产生的高额费用风险,让用户能够以更加经济实惠的方式获取稳定的代理 IP 服务,大幅降低了运营成本,大大提升了业务的经济效益。
二、准备阶段:必要的工具与环境
在开展Twitter趋势数据分析工作之前,以下是您需要准备的几样基本工具与资源:
-
Python开发环境:Python是数据分析领域的主力语言,推荐安装Anaconda,携带了丰富的科学计算库。
-
代理IP服务商账号:选择自己可信赖的代理IP服务提供商。
-
相关Python第三方库:
-
Pandas:用于处理数据表格。
-
Matplotlib和Seaborn:用于数据可视化。
-
通过安装以下命令完成依赖库的安装:
pip install tweepy pandas matplotlib seaborn三、实战操作
第一步:配置代理IP,连接目标地区
首先,为了确保脚本能通过特定地区IP访问Twitter,我们需要配置代理。
import requests
# 青果网络海外代理IP
proxy_url = "https://overseas.proxy.qg.net/get?key=yourkey&num=1&area=&isp=&format=txt&seq=\r\n&distinct=false"
# 测试代理是否可用
test_url = "https://httpbin.org/ip" # 用于显示当前IP
response = requests.get(test_url, proxies=proxies)
print("当前IP为:", response.json())推荐使用API自动获取可用IP地址,确保IP数据的动态性和稳定性。此外,在高并发数据采集中具有巨大优势。
第2步:解析Twitter趋势的HTML结构
研究Twitter数据的第一步始终是搞清楚网页的结构。趋势榜单是一个容器,所有的趋势内容都嵌套在类似的HTML结构里,我们可以通过浏览器开发者工具(F12)检查页面的HTML结构。
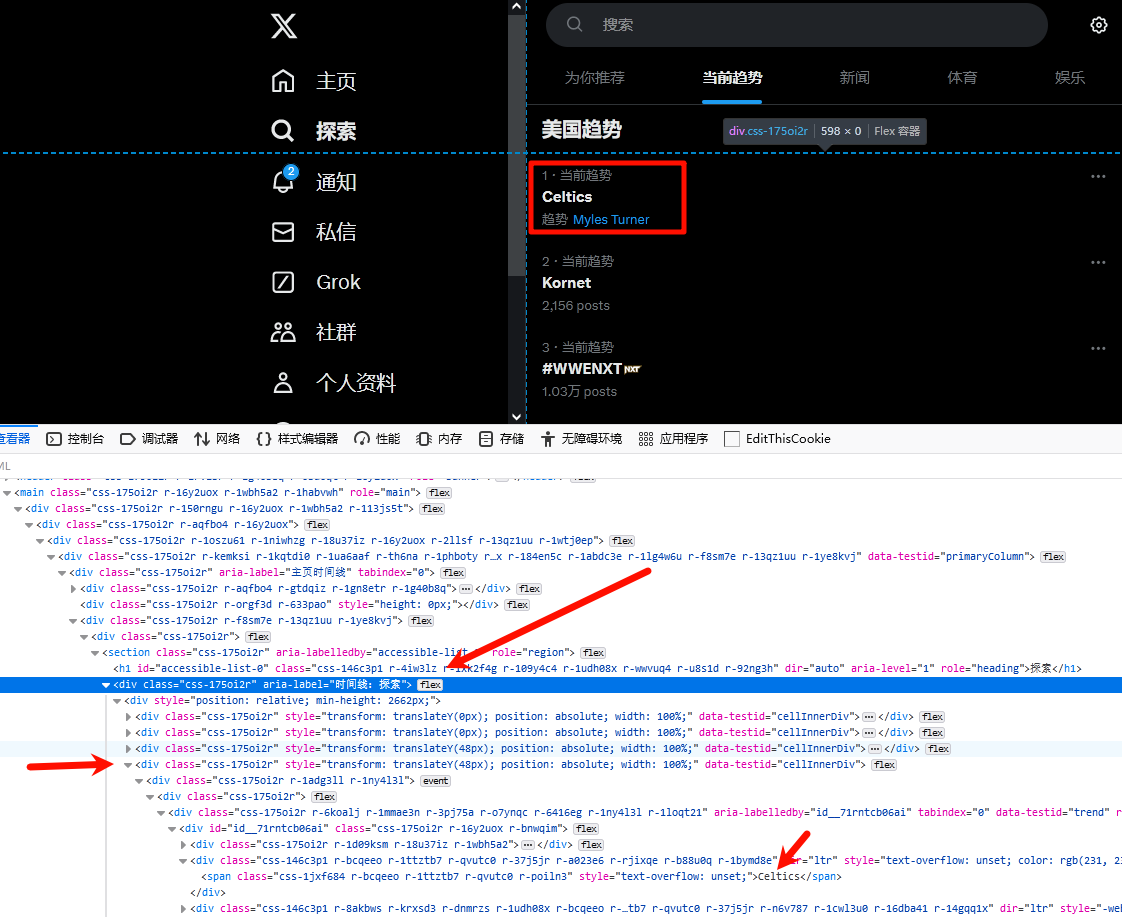
当你打开 Twitter 的“Explore”页面,可以发现趋势榜单的数据结构归属于一个 aria-label 属性为“时间线:探索”的 div 节点下。通过XPath路径解析,你可以轻松抓取到所需的趋势数据。
趋势板块的所有内容,都嵌套于一个主容器节点中:
<div aria-label="时间线:探索"><!-- 包含所有趋势信息的内容 -->
</div>
通过XPath路径解析,我们进一步确认每一条趋势关键字(如#WorldCup)位于<span>标签中。以下便是提取趋势内容的XPath://div[@aria-label="时间线:探索"]/div/div//div/div/div/div/div[2]/span简化来说,这是我们抓取趋势内容的入口!
第3步:撰写爬虫代码,结合海外代理IP
下面是一个Python数据采集的小例子,在这里我们通过requests调用目标页面,并结合代理IP来进行抓取。
核心代码如下:
import requests as rq
from bs4 import BeautifulSoup
# 模拟浏览器头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0",
}
# 目标URL
url = 'https://x.com/explore/tabs/keyword'
# 配置青果网络海外代理IP
proxy = {'https://overseas.proxy.qg.net/get?key=yourkey&num=1&area=&isp=&format=txt&seq=\r\n&distinct=false',
}
# 定义页面处理函数
def process_page(page_content):soup = BeautifulSoup(page_content, 'html.parser')trends = soup.select('div[aria-label="时间线:探索"] span')return [trend.get_text() for trend in trends]
# 请求页面数据
try:response = rq.get(url, headers=headers, proxies=proxy)if response.status_code == 200:trend_data = process_page(response.content)print("抓取到的趋势数据:", trend_data)else:print("请求失败,状态码:", response.status_code)
except Exception as e:print("请求过程中出错:", e)第四步:代理和多线程的配合使用
当批量抓取数据时,利用代理池和多线程请求可以极大提高效率:
import _thread
import time
def worker():# 重复调用爬虫代码流程response = rq.get(url, headers=headers, proxies=proxy)trend_data = process_page(response.content)print(trend_data) # 可进一步保存数据
for i in range(10): # 启动10个线程_thread.start_new_thread(worker, ())time.sleep(0.2)
time.sleep(5) # 等待所有线程结束第五步:数据存储与清洗
抓取的Twitter趋势数据格式为JSON。为了直观分析,我们需要将数据存储为表格文件(如CSV格式)。
以下是将趋势名称及推文量导出到CSV的代码:
import pandas as pd
# 示例数据清洗与存储
trends_list = trends_result[0]["trends"]
trends_df = pd.DataFrame(trends_list)
trends_df = trends_df[["name", "tweet_volume"]].dropna() # 去除为空的列
# 导出到CSV文件
trends_df.to_csv("twitter_trends.csv", index=False)
print("数据已保存为twitter_trends.csv")注意,有时可能会存在缺失值或无效值,这时需要特别处理,比如剔除None,或者填充默认值。
第六步:数据可视化分析
数值不直观?没关系!我们可以用可视化工具直观地展示不同话题的推文量以及趋势之间的变化。
import matplotlib.pyplot as plt
import seaborn as sns
# 数据可视化
plt.figure(figsize=(10, 6))
top_trends = trends_df.sort_values("tweet_volume", ascending=False).head(10)
sns.barplot(x="tweet_volume", y="name", data=top_trends, palette="vlag")
plt.title("Twitter趋势话题与推文量分析", fontsize=16)
plt.xlabel("推文量")
plt.ylabel("话题")
plt.show()通过图表,很容易发现当前哪些话题在Twitter上形成了热点,我们可以基于这些趋势预测事件发展或制定内容策略。
第七步:实战成果展示
| 主趋势词 | 热度级别 | 国家/区域 |
|---|---|---|
| MoonLanding | 高热 | 全球性 |
| Artificial Intelligence | 垂直趋势 | 美国 |
| Messi Scores | 短期热点 | 阿根廷 |
这样的趋势统计可以为用户画像分析、热点话题营销等实时决策提供数据支持。
四、总结
完成了Twitter趋势数据的抓取与分析,我们该如何更好地优化这一流程?
-
代理池机制:使用动态代理IP池,避免单一代理IP使用的异常风险。青果网络提供高度灵活的动态IP服务,适合此类需求。
-
扩展采集范围:除了趋势(Trending),也可以抓取更多字段数据,如某话题的评论互动,增加分析维度。
-
部署并行任务:通过分布式爬虫技术提升效率,例如使用多线程模式抓取全球多个城市数据。
这就是关于利用海外代理IP完成Twitter趋势数据分析的实战内容。从工具准备,到代理配置,再到数据抓取及分析,是全链路的一次深入体验。