婚礼摄影作品网站公众号推广渠道
深入理解GPT:架构、原理与应用示例
一、引言
GPT(Generative Pre-trained Transformer)系列模型自2018年问世以来,凭借其强大的文本生成能力和多任务适应性,彻底改变了自然语言处理(NLP)领域。本文将从架构设计、训练方法到实际应用,结合代码示例与架构图,带您全面理解GPT的核心原理。
二、GPT的核心架构
1. 整体架构图(文字描述)
输入文本 → [词嵌入层] → [位置编码层] → ↓
多层Transformer解码器(仅Decoder):├─ Masked Self-Attention层(遮蔽未来信息)├─ 前馈神经网络(FFN)└─ 残差连接 + 层归一化↓
输出层 → Softmax生成概率分布 → 下一个词预测
GPT主要基于 Transformer 解码器(Decoder-only),整体架构如下:
GPT由词嵌入(Embedding)、多层Transformer解码器、输出层 组成:
1️⃣ 输入嵌入(Token Embeddings):
- 使用 Byte-Pair Encoding(BPE) 进行子词分词,将文本转换为 token。
- 通过 词嵌入矩阵 将 token 映射为固定维度的向量。
2️⃣ 位置编码(Positional Encoding):
- GPT 使用 可训练的位置嵌入(Learnable Positional Embeddings),不像 BERT 采用固定三角函数编码。
3️⃣ 多层 Transformer 解码器(Multi-layer Decoder):
- 由多个 自注意力(Self-Attention)、前馈神经网络(FFN)、残差连接(Residual Connections) 组成。
- Masked Self-Attention 机制,确保每个 token 只能看到 之前的 token,防止未来信息泄露。
4️⃣ 输出层(Output Layer):
- 经过线性变换 + Softmax计算概率分布,生成下一个token。
看三个语言模型的对比架构图, 中间的就是GPT:
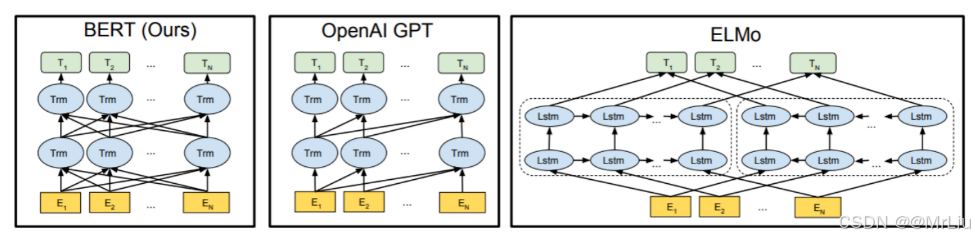
从上图可以很清楚的看到GPT采用的是单向Transformer模型, 例如给定一个句子[u1, u2, …, un], GPT在预测单词ui的时候只会利用[u1, u2, …, u(i-1)]的信息, 而BERT会同时利用上下文的信息[u1, u2, …, u(i-1), u(i+1), …, un]。
作为两大模型的直接对比, BERT采用了Transformer的Encoder模块, 而GPT采用了Transformer的Decoder模块。并且GPT的Decoder Block和经典Transformer Decoder Block还有所不同, 如下图所示:
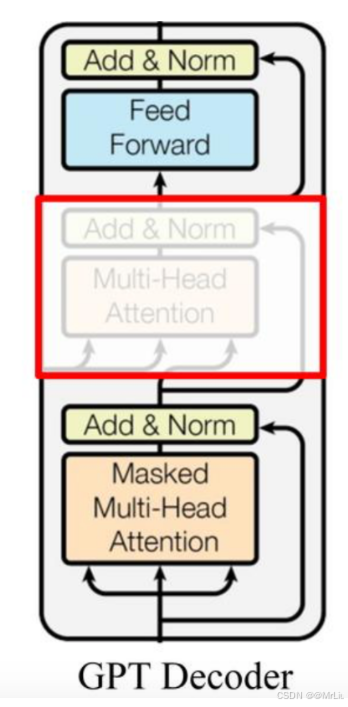
如上图所示, 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层。但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层。
作为单向Transformer Decoder模型, GPT利用句子序列信息预测下一个单词的时候, 要使用Masked Multi-Head Attention对单词的下文进行遮掩(look ahead mask), 来防止未来信息的提前泄露。例如给定一个句子包含4个单词[A, B, C, D], GPT需要用[A]预测B, 用[A, B]预测C, 用[A, B, C]预测D。很显然的就是当要预测B时, 需要将[B, C, D]遮掩起来。
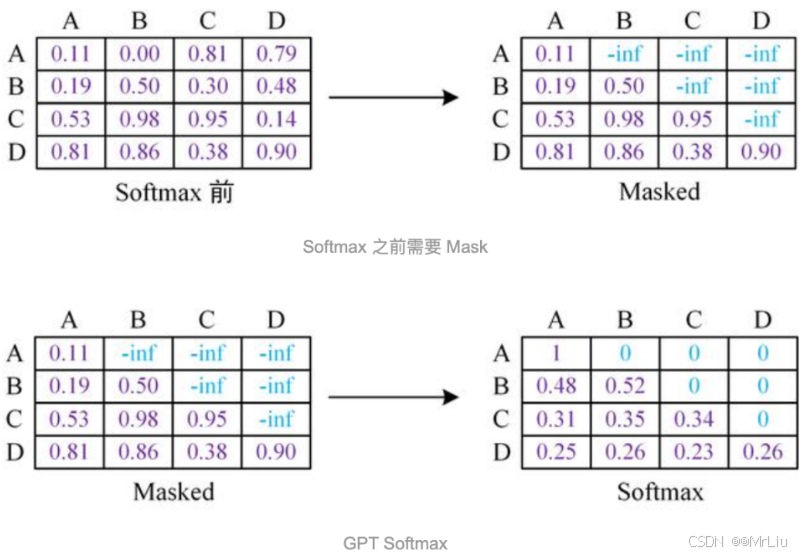
具体的遮掩操作是在slef-attention进行softmax之前进行的, 一般的实现是将MASK的位置用一个无穷小的数值-inf来替换, 替换后执行softmax计算得到新的结果矩阵,这样-inf的位置就变成了0。如上图所示, 最后的矩阵可以很方便的做到当利用A预测B的时候, 只能看到A的信息; 当利用[A, B]预测C的时候, 只能看到A, B的信息。
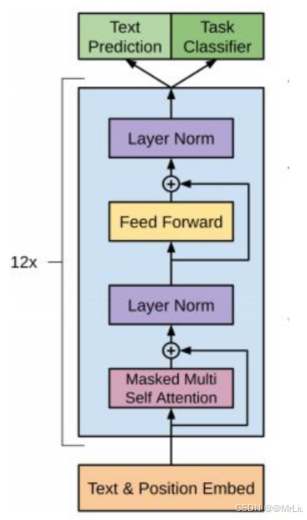
注意:对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block。
2. 关键组件详解
(1)词嵌入与位置编码
- 词嵌入:通过Byte-Pair Encoding(BPE)将文本切分为子词单元(如
"Transformer"→["Trans", "former"]),再映射为稠密向量。 - 位置编码:GPT使用可学习的位置嵌入(区别于BERT的固定三角函数编码),为模型注入序列顺序信息。
(2)Transformer解码器
GPT仅使用Transformer的解码器(Decoder)部分,核心组件包括:
-
- 自注意力层(Self-Attention Layer)
- 计算输入序列中每个词与其他词的相关性,动态分配权重。
- 公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V - Q Q Q(Query)、 K K K(Key)、 V V V(Value)为线性变换后的向量。
- d k d_k dk为缩放因子,防止内积过大。
-
- 前馈神经网络(Feed-Forward Network)
- 对每个词的表示进行非线性变换(如ReLU)。
-
- 残差连接与层归一化
- 每个子层后添加残差连接(Residual Connection)和层归一化(LayerNorm),缓解梯度消失。
- Masked Self-Attention:通过
look-ahead mask确保预测第i个词时只能看到前i-1个词。例如:# 遮蔽矩阵示例(4词序列) [[0, -inf, -inf, -inf],[0, 0, -inf, -inf],[0, 0, 0, -inf],[0, 0, 0, 0]] - 堆叠结构:GPT-3使用48-96层解码器,每层包含:
- 多头自注意力(16-32头)
- 前馈网络(ReLU激活)
- 残差连接与层归一化
三、训练方法与关键技术
1. 预训练流程
# 损失函数:最大化下一个词的对数似然
def pretrain_loss(logits, labels):return -tf.reduce_mean(tf.math.log(tf.nn.softmax(logits))[labels])
- 数据:互联网文本(网页、书籍等)
- 任务:预测被遮蔽的下一个词(自回归任务)
2. 微调策略
# 文本分类任务示例(添加分类头)
class GPTClassifier(tf.keras.Model):def __init__(self, base_model, num_classes):super().__init__()self.gpt = base_modelself.cls_head = tf.keras.layers.Dense(num_classes)def call(self, inputs):outputs = self.gpt(inputs)return self.cls_head(outputs[:, 0, :]) # 取[CLS]位置输出
3. 创新技术
- 上下文窗口扩展:GPT-4支持32768 token超长上下文
- 指令微调(Instruction Tuning):通过人类指令数据(如"请翻译这句话")对齐模型输出
四、代码示例:文本生成与问答
1. 文本生成(GPT-2)
from transformers import GPT2LMHeadModel, GPT2Tokenizermodel = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")input_text = "人工智能的未来发展趋势是"
inputs = tokenizer(input_text, return_tensors="pt")# 生成参数详解
outputs = model.generate(**inputs,max_length=50,temperature=0.7, # 控制随机性(0.0-确定性,1.0-随机)top_k=50, # 限制候选词数量do_sample=True # 启用采样策略
)print(tokenizer.decode(outputs[0]))
2. 问答任务(GPT-3风格)
input_text = "Q: 什么是Transformer模型?\nA:"
inputs = tokenizer(input_text, return_tensors="pt")outputs = model.generate(**inputs,max_length=100,num_beams=5, # 束搜索提升质量early_stopping=True
)print(tokenizer.decode(outputs[0]))
# 输出示例:"A: Transformer是一种基于自注意力机制的神经网络架构..."
五、架构对比与演进
| 版本 | 参数量 | 关键改进 | 应用场景 |
|---|---|---|---|
| GPT-1 | 1.17亿 | 基础Transformer解码器 | 基础文本生成 |
| GPT-2 | 15亿 | WebText预训练,Zero-shot | 多任务泛化 |
| GPT-3 | 1750亿 | Few-shot学习,API服务 | 代码生成、复杂推理 |
| GPT-4 | 未知 | 多模态支持,32K上下文 | 长文本分析、视觉推理 |
六、优缺点分析
优势
- 生成质量:可生成连贯的长文本(如小说章节)
- 上下文理解:捕捉跨句依赖(如代词消解)
- 任务泛化:通过提示词(Prompt)完成未见过的任务
局限
- 计算成本:GPT-3单次推理需约350W参数计算
- 事实幻觉:可能生成看似合理但错误的内容
- 单向性:传统GPT仅利用左侧上下文(GPT-3后引入双向注意力改进)
七、总结与展望
GPT通过预训练-微调范式与大规模Transformer架构,重新定义了NLP的边界。未来发展方向包括:
- 多模态融合:结合文本、图像、音频(如GPT-4V)
- 推理强化:通过RLHF(人类反馈强化学习)提升逻辑性
- 效率优化:稀疏注意力、模型蒸馏等技术降低计算成本
附录:架构图绘制建议
使用工具如draw.io或Mermaid绘制以下结构: