湖南网站备案要多少天软文范例大全
一、TL;DR
- Loss与模型size、数据集大小以及用于训练的计算量呈幂律关系
- 其他架构细节,如网络宽度或深度,在较宽范围内影响极小
- 简单的公式可以描述过拟合与模型/数据集大小的依赖关系,以及训练速度与模型大小的依赖关系
- 作用:固定计算预算的最优分配。更大的模型显著更样本高效
- 记住标红的小节结论就行了,重要的是结论和学习如何做消融实验的思路
二、引言/简单介绍
2.1 为什么要做
实证研究Transformer 架构的语言建模损失对模型架构、模型大小、训练资源以及用于训练过程的数据这些因素的依赖关系
2.2 有什么结论
-
模型性能主要依赖于规模,包括三个因素:模型参数的数量 N、数据集的大小 D 和用于训练的计算量 C。在合理范围内,性能对其他架构超参数(如深度与宽度)的依赖性非常弱
-
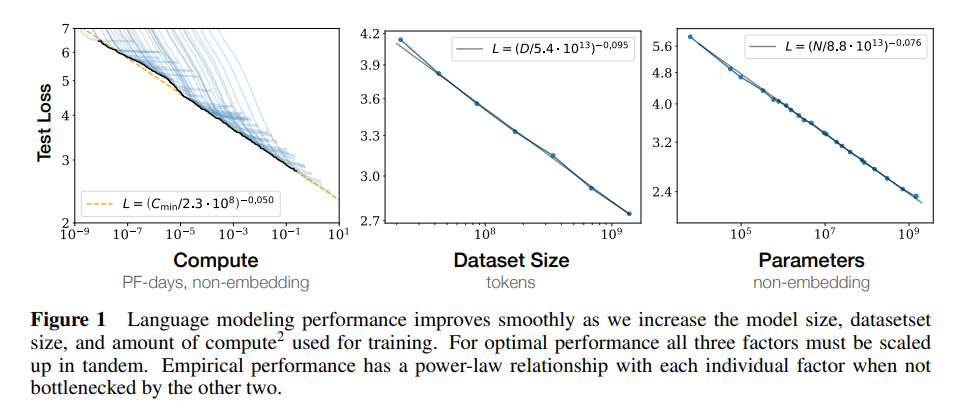
平滑的幂律关系:当不被其他两个因素限制时,性能与三个规模因素 N、D、C 呈幂律关系,趋势跨越超过六个数量级(见图1)。
-
过拟合的普遍性:只要我们同时扩大 N 和 D,性能就会可预测地提高,但如果固定其中一个而增加另一个,则进入收益递减的阶段。性能惩罚可预测地取决于比率
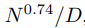 ,这意味着每当我们增加模型大小8倍时,我们只需要增加大约5倍的数据来避免惩罚。
,这意味着每当我们增加模型大小8倍时,我们只需要增加大约5倍的数据来避免惩罚。 -
训练的普遍性:训练曲线遵循可预测的幂律,其参数大致与模型大小无关。通过外推训练曲线的早期部分,我们可以大致预测如果训练时间更长会达到的损失。(第5节)
-
迁移性能与测试性能相关:当我们对模型在与训练数据分布不同的文本上进行评估时,结果与训练验证集上的结果强相关,损失上有一个大致恒定的偏移量——换句话说,迁移到不同的分布会带来一个恒定的惩罚,但除此之外,性能大致与训练集上的表现一致。(第3.2.2节)
-
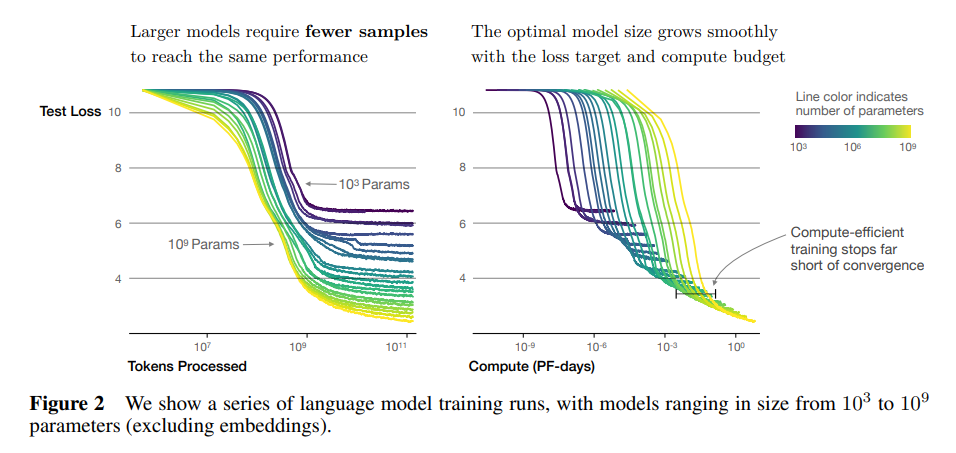
样本效率:大模型比小模型更样本高效,以更少的优化步骤(见图2)和更少的数据点(见图4)达到相同水平的性能。
-
-
收敛效率低:在固定计算预算 C 的情况下,但不对模型大小 N 或可用数据 D 进行其他限制时,我们通过训练非常大的模型并显著早于收敛时停止训练来获得最佳性能(见图3)。因此,最大计算效率的训练会比基于将小模型训练到收敛的预期更样本高效,数据需求随着训练计算量 C 的增加而非常缓慢地增长,D∼C0.27。(第6节)
-
最佳批量大小:训练这些模型的理想批量大小大致是损失的幂,通过测量梯度噪声规模 [MKAT18] 来确定;对于我们能够训练的最大模型,在收敛时大约为100万到200万标记。(第5.1节)
综合来看,这些结果表明,当我们适当地扩大模型大小、数据和计算量时,语言建模性能会平稳且可预测地提高。我们预计,更大的语言模型将比当前模型表现更好且更样本高效。
2.3 scaling law 总结
当性能仅受非嵌入参数数量 N 、数据集大小 D 或最大分配计算预算 Cmin 限制时,可以使用幂律定律来预测基于Transformer的自回归语言模型的测试损失值(图1)::
-
对于参数数量有限的模型,在足够大的数据集上训练到收敛:
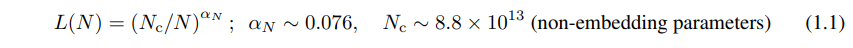
-
对于在有限数据集上训练的大模型,采用早期停止:
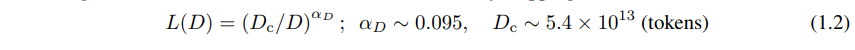
-
当训练的计算量有限,数据集足够大,模型大小合适,批量大小足够小(充分利用计算量)时:
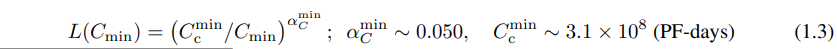
这些关系在 Cmin 的八个数量级、N 的六个数量级和 D 的两个数量级以上都成立。它们对模型形状和其他 Transformer 超参数(深度、宽度、自注意力头的数量)的依赖性非常弱
决定数据并行的速度/效率权衡的关键批量大小也大致遵循 L 的幂律:
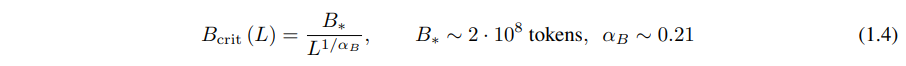
方程(1.1)和(1.2)一起表明,当我们增加模型大小时,我们应该根据 D∝NαN/αD∼N0.74 次线性地增加数据集大小。实际上,我们发现有一个结合了(1.1)和(1.2)的单一方程,它同时依赖于 N 和 D,并决定了过拟合的程度:
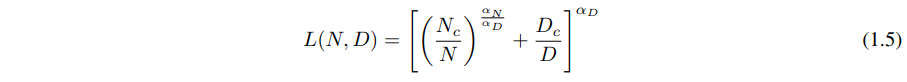
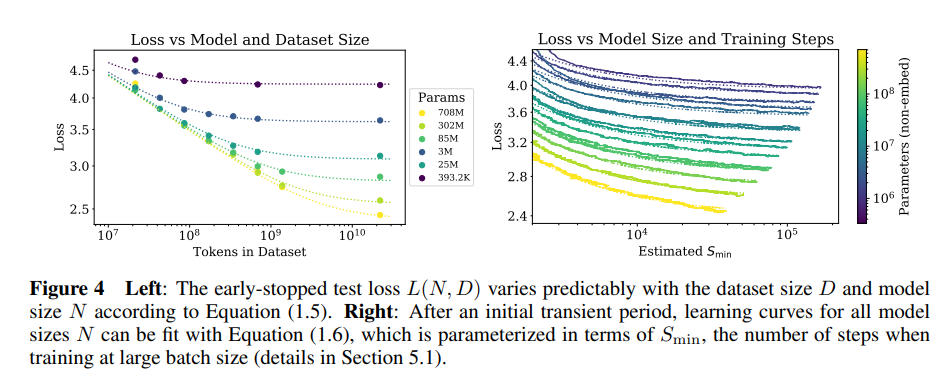
拟合结果如图4左侧所示。我们推测这种函数形式也可能参数化其他生成式建模任务的训练对数似然。
当在无限数据限制下,以有限的参数更新步数 S 训练给定模型时,在初始瞬态期之后,学习曲线可以准确地拟合为(见图4右侧):
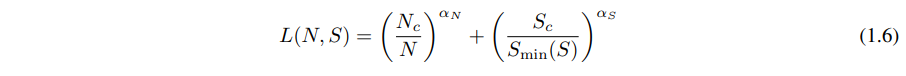
其中 Sc≈2.1×103,αS≈0.76,Smin(S) 是使用方程(5.4)估计的最小可能的优化步数(参数更新)。
在固定计算预算 C 的情况下,但没有其他限制时,方程(1.6)导致预测最优模型大小 N、最优批量大小 B、最优步数 S 和数据集大小 D 应该按以下方式增长:
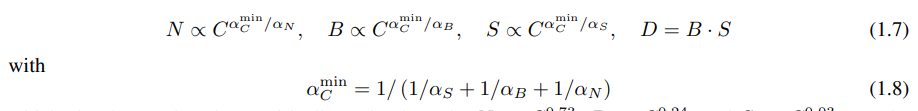
以下内容与经验上最优的结果最为接近:![]() 。
。
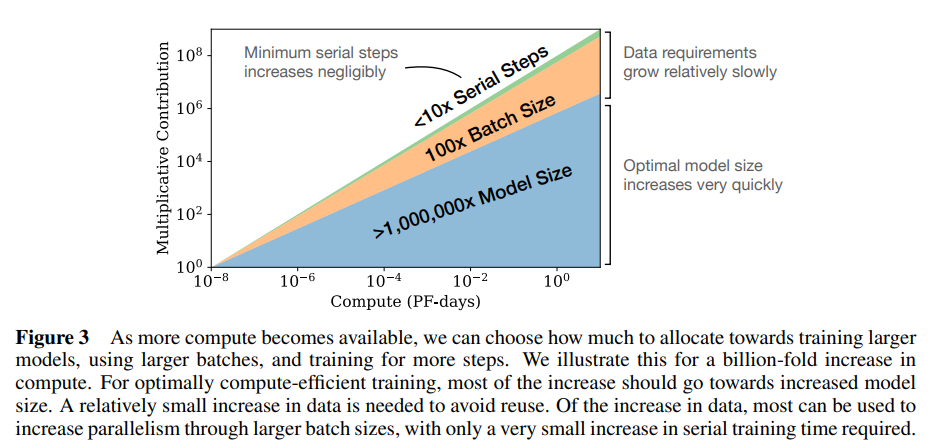 随着计算预算 C 的增加,主要应将其用于更大规模的模型,而无需显著增加训练时间或数据集规模(见图 3)。这也意味着,随着模型规模的增大,它们变得越来越样本高效。在实践中,由于硬件限制,研究人员通常会训练比最大计算效率低的小型模型更长时间。最优性能取决于总计算量的幂律(见方程(1.3))
随着计算预算 C 的增加,主要应将其用于更大规模的模型,而无需显著增加训练时间或数据集规模(见图 3)。这也意味着,随着模型规模的增大,它们变得越来越样本高效。在实践中,由于硬件限制,研究人员通常会训练比最大计算效率低的小型模型更长时间。最优性能取决于总计算量的幂律(见方程(1.3))
2.4 符号说明
我们使用以下符号:
• L —— 交叉熵损失,单位为纳特(nats)。通常它是对上下文中的标记进行平均计算的,但在某些情况下,我们会报告上下文中特定标记的损失。
• N —— 模型参数的数量,不包括所有词汇表和位置嵌入。
• C≈6NBS —— 总非嵌入训练计算量的估计值,其中 B 是批量大小,S 是训练步数(即参数更新次数)。我们用 PF-days(千万亿次浮点运算天数)来表示数值,其中 1 PF-day = 1015×24×3600=8.64×1019 次浮点运算。
• D —— 数据集大小,以标记数量为单位。
• Bcrit —— 临界批量大小 [MKAT18],定义和讨论见第 5.1 节。在临界批量大小下进行训练,大致可以在时间和计算效率之间达到最优平衡。
• Cmin —— 达到给定损失值所需的最小非嵌入计算量的估计值。如果模型在远小于临界批量大小的批量下进行训练,就会使用这种训练计算量。
• Smin —— 达到给定损失值所需的最小训练步数的估计值。如果模型在远大于临界批量大小的批量下进行训练,也会使用这种训练步数。
• αX —— 损失按幂律缩放的指数,表示为 L(X)∝1/XαX,其中 X 可以是 N、D、C、S、B 或 Cmin。
三、方法和细节
这一大节主要是定义transformer的理论计算量,训练过程和数据集简介,用来做消融实验(没兴趣略过不看就好)
使用数据集和token方法: WebText2,WebText [RWC+19] 数据集的扩展版本,使用字节对编码 [SHB15] 进行标记化,词汇表大小为 nvocab=50257
性能指标:1024 个token的上下文中平均计算的自回归对数似然(即交叉熵损失)
模型:解码器 [LSP+18, RNSS18] Transformer [VSP+17] 模型,额外也训练了 LSTM 模型和通用 Transformer [DGV+18] 用于比较。
3.1 Transformer 的参数和计算量缩放
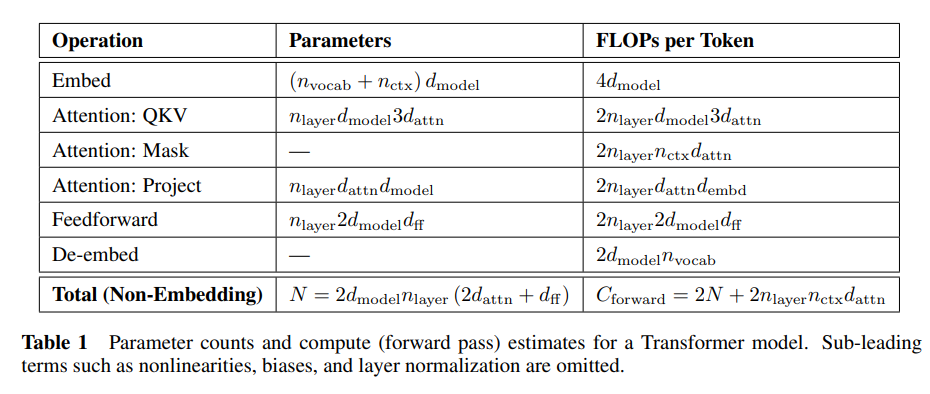
我们使用超参数 nlayer(层数)、dmodel(残差流的维度)、dff(中间前馈层的维度)、dattn(注意力输出的维度)和 nheads(每层的注意力头数)来参数化 Transformer 架构。我们在输入上下文中包含 nctx 个标记,除非另有说明,否则 nctx=1024。
我们用 N 来表示模型大小,定义为非嵌入参数的数量:
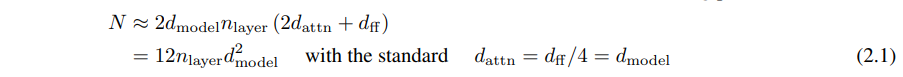
其中我们排除了偏差和其他次要项。我们的模型在嵌入矩阵中有 nvocab*dmodel 个参数,并且使用 nctx*dmodel 个参数用于position embedding,但在讨论“模型大小”N 时我们不包括这些参数;我们会发现这会产生更清晰的缩放定律。
计算 Transformer 的前向传播大致涉及:
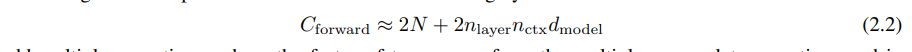
次加法-乘法运算,其中的 2 来自于矩阵乘法中使用的乘积累加操作。更详细的逐操作参数和计算量统计包含在表 1 中。对于 dmodel>nctx/12 的上下文和模型,每个标记的上下文依赖计算成本是总计算量的一个相对较小的部分。由于我们主要研究的是 dmodel≫nctx/12 的模型,因此我们在训练计算量估计中不包括上下文依赖项。考虑到反向传播(大约是前向传播的两倍计算量),我们定义估计的非嵌入计算量为每个训练标记大约 C≈6N 次浮点运算。
3.2 训练过程
使用 Adam 优化器 以固定的 2.5×105 步训练模型,每步的批量大小为 512 个 1024 个token的序列。由于内存限制,我们最大的模型(参数超过 10 亿)是使用 Adafactor [SS18] 训练的。我们尝试了各种学习率和学习率计划,如附录 D.6 所述。我们发现收敛时的结果在很大程度上与学习率计划无关。除非另有说明,我们数据中包含的所有训练运行都使用了学习率计划,即先进行 3000 步的线性热身,然后进行余弦衰减至零。
3.3 数据集
我们在 [RWC+19] 中描述的 WebText 数据集的扩展版本上训练我们的模型。原始的 WebText 数据集是 2017 年 12 月之前 Reddit 外部链接的网络抓取数据,这些链接至少获得了 3 个赞。在第二个版本 WebText2 中,我们添加了 2018 年 1 月至 10 月期间的 Reddit 外部链接,这些链接也至少获得了 3 个赞。赞的阈值作为人们是否认为链接有趣或有用的启发式标准。我们使用 Newspaper3k Python 库提取了新链接的文本。总共,该数据集包含 2030 万篇文档,包含 96 GB 的文本和 16.2 亿个单词(按 wc 定义)。然后我们应用 [RWC+19] 中描述的可逆分词器,得到 22.9 亿个标记。我们保留其中 6.6 亿个标记作为测试集,我们还在类似准备的书籍语料库 [ZKZ+15]、Common Crawl [Fou]、英文维基百科和一系列公开可用的网络书籍样本上进行测试。
四、实证结果与基本幂律
这一节主要讲实验结果,需要重点关注
为了描述语言模型的扩展特性,我们训练了各种各样的模型,改变了多个因素,包括:
-
模型大小(从 768 个non-embedding parameters 到 15 亿个non-embedding parameters)
-
数据集大小(从 2200 万个token到 230 亿个token)
-
形状(包括深度、宽度、注意力头数和前馈层维度)
-
上下文长度(大多数情况下为 1024,但我们也在较短的上下文中进行了实验)
-
批量大小(大多数情况下为 219,但我们也会改变它以测量临界批量大小)
在本节中,我们将展示数据以及基于实证的拟合结果,将理论分析推迟到后续章节。
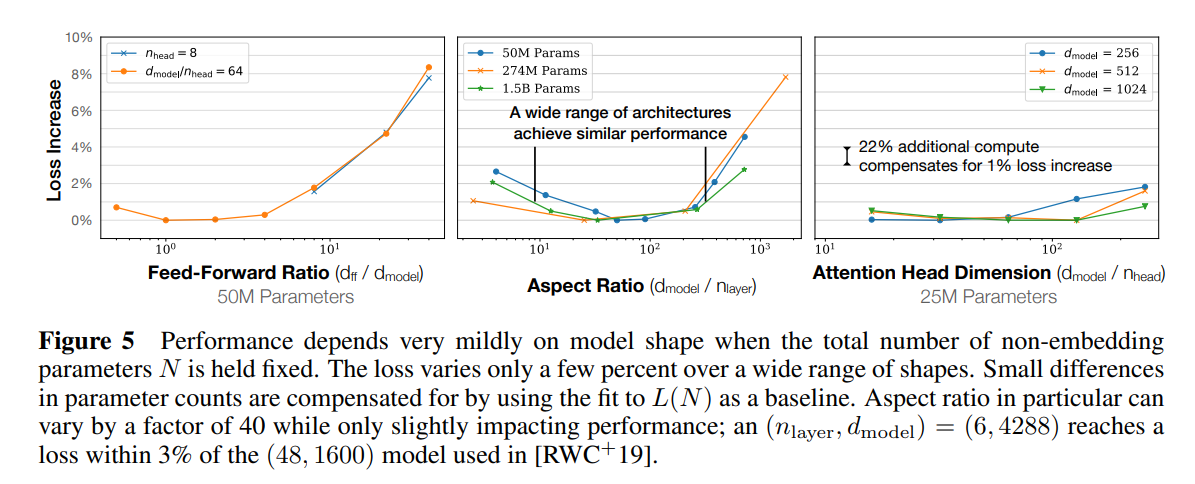
4.1 Transformer 的形状和超参数的独立性
小节结论:当保持总non-embedding parameters N 不变时,Transformer 的性能对形状参数 nlayer、nheads 和 dff 的依赖性非常弱。
验证方法:在保持固定大小的同时改变单个超参数。
- 对于 nheads 的情况,当改变 nlayer 时,我们同时改变 dmodel,同时保持 N≈12nlayerdmodel2 不变。
- 为了在固定模型大小的情况下改变 dff,我们也会同时改变 dmodel 参数,这是由表 1 中的参数计数所要求的。如果更深的 Transformer 有效地表现得像较浅模型的集成,那么 nlayer 的独立性就会随之而来,这已经为 ResNets [VWB16] 提出过。结果如图 5 所示。
下图结论:当保持总非嵌入参数数量 N 不变时,性能对模型形状的依赖性非常小。在广泛的形状范围内,损失仅变化几个百分点。
4.2 非嵌入参数数量 N 与性能
小节结论:当包括嵌入参数时,性能似乎除了参数数量外还强烈依赖于层数
在图 6 中,我们展示了从形状为 (nlayer,dmodel)=(2,128) 的小型模型到拥有数十亿参数的模型(形状从 (6,4288) 到 (207,768))的广泛模型的性能。在这里,我们在完整的 WebText2 数据集上训练到接近收敛,并观察到没有过拟合(除了可能对于非常大的模型)。
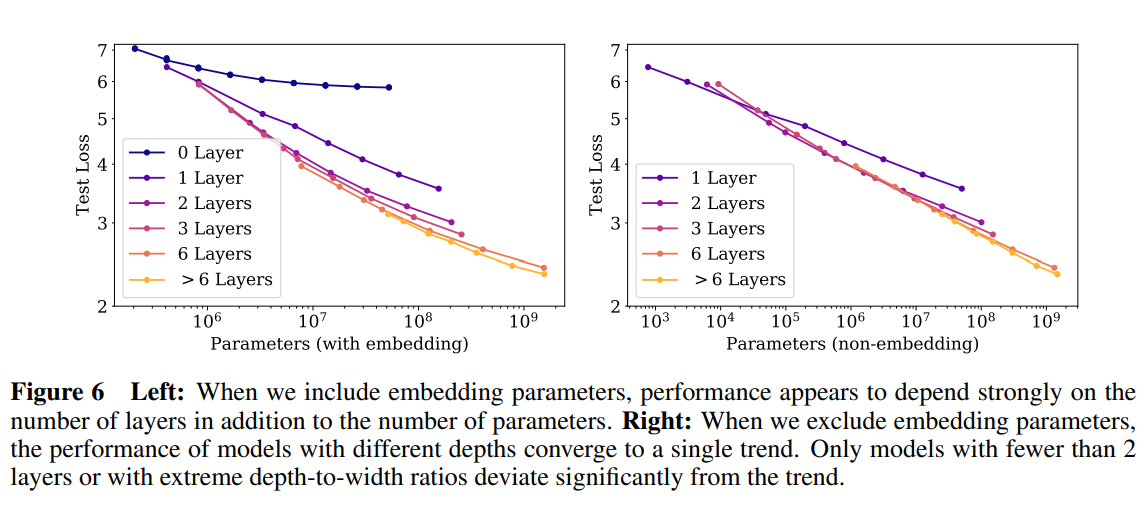
左边:当我们包括嵌入参数时,性能似乎除了依赖于参数数量外,还强烈依赖于层数。
右边:当我们排除嵌入参数时,不同深度的模型的性能汇聚到一条趋势线上。只有少于2层的模型或具有极端深度与宽度比例的模型才会显著偏离该趋势。
如图 1 所示,我们发现随着非嵌入参数数量 N 的增加,性能呈现出稳定的趋势,可以拟合到方程(1.5)的第一项,因此有:
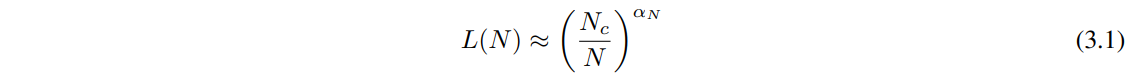
为了观察这些趋势,研究性能作为 N 的函数至关重要;如果我们使用总参数数量(包括嵌入参数),趋势会变得不那么明显(见图 6)。这表明嵌入矩阵可以变得更小而不会影响性能,正如最近的研究 [LCG+19] 所看到的那样。
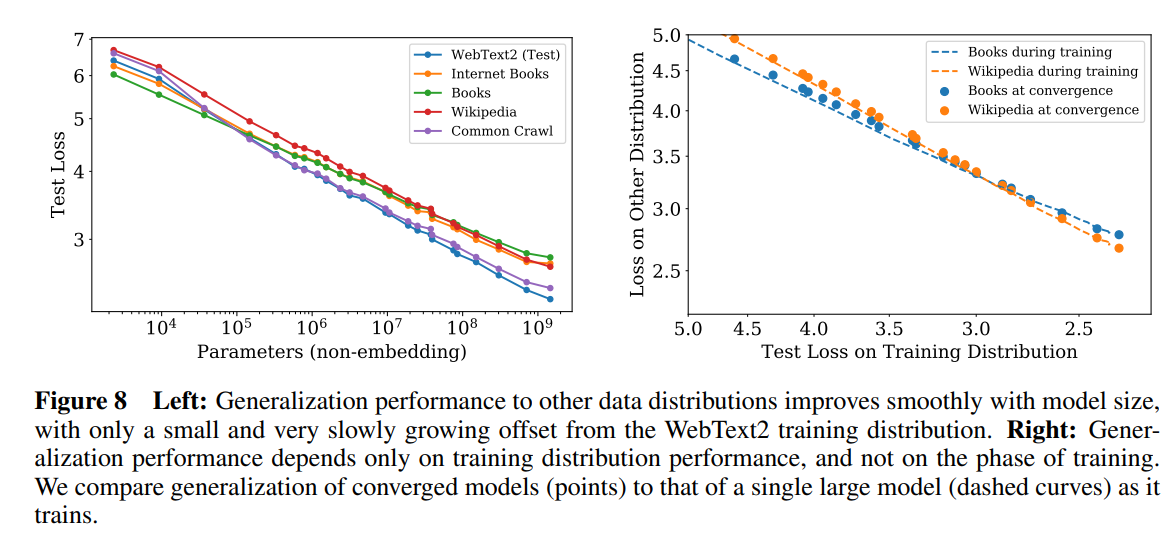
尽管这些模型是在 WebText2 数据集上训练的,但它们在各种其他数据集上的测试损失也是 N 的幂律,且幂几乎相同,如图 8 所示。
4.2.1 与 LSTM 和通用 Transformer 的比较
小节结论:Tansformer的性能在训练早期和LSTM性能相当,后期出现明显差异
在图 7 中,我们比较了 LSTM 和 Transformer 的性能,作为非嵌入参数数量 N 的函数。LSTM 使用相同的数据集和上下文长度进行训练。从这些图表中,我们看到 LSTM 在上下文中早期出现的标记上的表现与 Transformer 相当,但对于后期的标记则无法与 Transformer 的性能相匹配。我们在附录 D.5 中展示了性能与上下文位置之间的幂律关系,其中对于较大的模型,越来越大的幂表明了快速识别模式的能力有所提高。
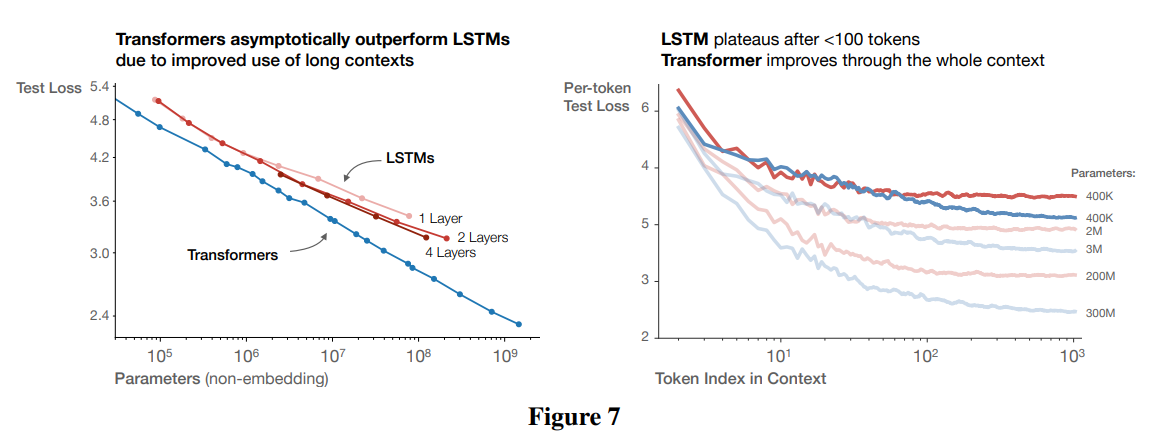
我们还在附录中的图 17 中比较了标准 Transformer 与循环 Transformer [DGV+18] 的性能。这些模型重用了参数,因此作为 N 的函数,它们的表现略好一些,但代价是每个参数的额外计算量。
4.2.2 在数据分布之间的泛化能力
我们还在一组额外的文本数据分布上测试了我们的模型。这些数据集上的测试损失作为模型大小的函数如图 8 所示;在所有情况下,模型仅在 WebText2 数据集上进行了训练。我们看到,这些其他数据分布上的损失随着模型大小的增加而平稳改善,与 WebText2 上的改善直接平行。我们发现泛化能力几乎完全取决于分布内的验证损失,而不依赖于训练的持续时间或是否接近收敛。我们也没有观察到对模型深度的依赖(见附录 D.8)。
4.3 数据集大小和计算量与性能
小节结论:测试损失作为数据集大小 D(以标记为单位)和训练计算量 C 的趋势如图1所示
对于 D 的趋势,我们训练了一个 (nlayer,nembd)=(36,1280) 的模型,在 WebText2 数据集的固定子集上进行训练。一旦测试损失停止下降,我们就停止训练。我们看到,得到的测试损失可以用简单的幂律来拟合:
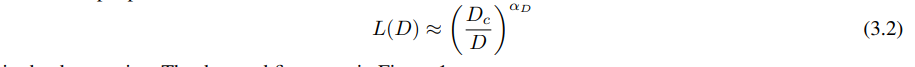
训练期间使用的总非嵌入计算量可以估计为![]() ,其中 B 是批量大小,S 是参数更新的次数,6 这个因子考虑了前向和反向传播。因此,对于给定的 C 值,我们可以扫描具有不同 N 的所有模型,以找到在步骤
,其中 B 是批量大小,S 是参数更新的次数,6 这个因子考虑了前向和反向传播。因此,对于给定的 C 值,我们可以扫描具有不同 N 的所有模型,以找到在步骤 ![]() 上表现最佳的模型。
上表现最佳的模型。
结果如图 1 左侧图表中的粗黑线所示。它可以拟合为:
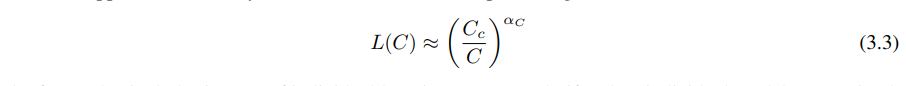
该图表还包括各个学习曲线的图像,以澄清单个模型何时处于最优状态。我们将在后面更仔细地研究计算量的最优分配。数据强烈表明,样本效率随着模型大小的增加而提高,我们还在附录中的图 19 中直接说明了这一点。
五、探索无限数据的极限和过拟合现象
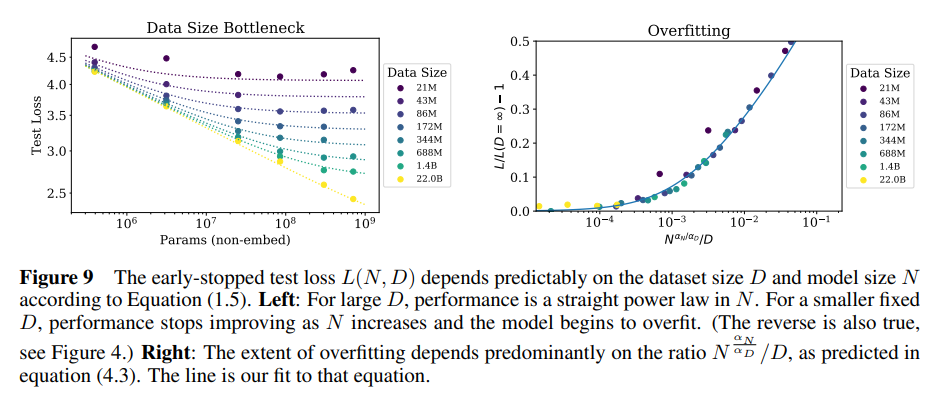
核心结论:
- 对于较大的D,性能是N的直线幂律。对于较小的固定D,随着N的增加,性能停止提高,模型开始过拟合。
- 过度拟合的程度主要取决于方程(4.3)
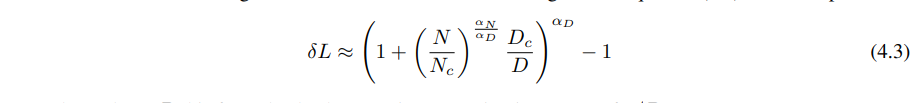
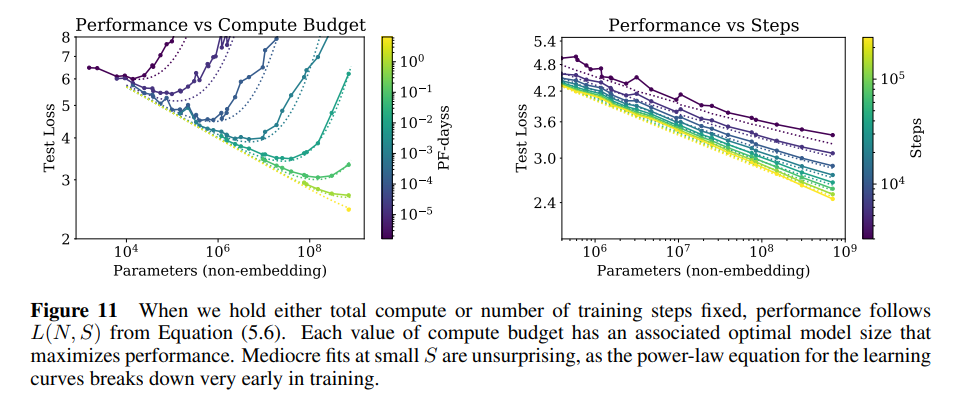
六、模型大小和训练时间的缩放定律
核心结论:
- 当保持总计算量或训练步骤数不变时,性能遵循方程式(5.6)。每个计算预算值都有一个相关的最佳模型大小,可以最大化性能。
- 在小S值下,模型出现中等拟合现象,因为学习曲线的幂律方程在训练早期就会崩溃。
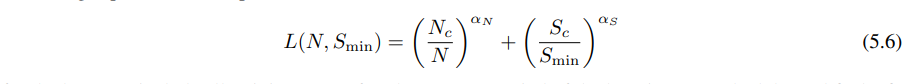
6.1 如何寻找最佳的模型大小
结论:
- 定一个固定的计算预算,一个特定的模型大小是最优的
- 大于计算效率大小的模型需要更少的训练步