邢台企业网站建设咨询如何做宣传推广效果最好
Lag-Llama: Towards Foundation Models for Time Series Forecasting
文章内容:
时间序列预测任务,单变量预测单变量,基于Llama大模型,在zero-shot场景下模型表现优异。创新点,引入滞后特征作为协变量来进行预测。
获得不同频率的lag,来自glunoTS库里面的源码
def _make_lags(middle: int, delta: int) -> np.ndarray:"""Create a set of lags around a middle point including +/- delta."""return np.arange(middle - delta, middle + delta + 1).tolist()def get_lags_for_frequency(freq_str: str,lag_ub: int = 1200,num_lags: Optional[int] = None,num_default_lags: int = 7,
) -> List[int]:"""Generates a list of lags that that are appropriate for the given frequencystring.By default all frequencies have the following lags: [1, 2, 3, 4, 5, 6, 7].Remaining lags correspond to the same `season` (+/- `delta`) in previous`k` cycles. Here `delta` and `k` are chosen according to the existing code.Parameters----------freq_strFrequency string of the form [multiple][granularity] such as "12H","5min", "1D" etc.lag_ubThe maximum value for a lag.num_lagsMaximum number of lags; by default all generated lags are returned.num_default_lagsThe number of default lags; by default it is 7."""# Lags are target values at the same `season` (+/- delta) but in the# previous cycle.def _make_lags_for_second(multiple, num_cycles=3):# We use previous ``num_cycles`` hours to generate lagsreturn [_make_lags(k * 60 // multiple, 2) for k in range(1, num_cycles + 1)]def _make_lags_for_minute(multiple, num_cycles=3):# We use previous ``num_cycles`` hours to generate lagsreturn [_make_lags(k * 60 // multiple, 2) for k in range(1, num_cycles + 1)]def _make_lags_for_hour(multiple, num_cycles=7):# We use previous ``num_cycles`` days to generate lagsreturn [_make_lags(k * 24 // multiple, 1) for k in range(1, num_cycles + 1)]def _make_lags_for_day(multiple, num_cycles=4, days_in_week=7, days_in_month=30):# We use previous ``num_cycles`` weeks to generate lags# We use the last month (in addition to 4 weeks) to generate lag.return [_make_lags(k * days_in_week // multiple, 1)for k in range(1, num_cycles + 1)] + [_make_lags(days_in_month // multiple, 1)]def _make_lags_for_week(multiple, num_cycles=3):# We use previous ``num_cycles`` years to generate lags# Additionally, we use previous 4, 8, 12 weeksreturn [_make_lags(k * 52 // multiple, 1) for k in range(1, num_cycles + 1)] + [[4 // multiple, 8 // multiple, 12 // multiple]]def _make_lags_for_month(multiple, num_cycles=3):# We use previous ``num_cycles`` years to generate lagsreturn [_make_lags(k * 12 // multiple, 1) for k in range(1, num_cycles + 1)]# multiple, granularity = get_granularity(freq_str)offset = to_offset(freq_str)# normalize offset name, so that both `W` and `W-SUN` refer to `W`offset_name = norm_freq_str(offset.name)if offset_name == "A":lags = []elif offset_name == "Q":assert (offset.n == 1), "Only multiple 1 is supported for quarterly. Use x month instead."lags = _make_lags_for_month(offset.n * 3.0)elif offset_name == "M":lags = _make_lags_for_month(offset.n)elif offset_name == "W":lags = _make_lags_for_week(offset.n)elif offset_name == "D":lags = _make_lags_for_day(offset.n) + _make_lags_for_week(offset.n / 7.0)elif offset_name == "B":lags = _make_lags_for_day(offset.n, days_in_week=5, days_in_month=22) + _make_lags_for_week(offset.n / 5.0)elif offset_name == "H":lags = (_make_lags_for_hour(offset.n)+ _make_lags_for_day(offset.n / 24)+ _make_lags_for_week(offset.n / (24 * 7)))# minuteselif offset_name == "T":lags = (_make_lags_for_minute(offset.n)+ _make_lags_for_hour(offset.n / 60)+ _make_lags_for_day(offset.n / (60 * 24))+ _make_lags_for_week(offset.n / (60 * 24 * 7)))# secondelif offset_name == "S":lags = (_make_lags_for_second(offset.n)+ _make_lags_for_minute(offset.n / 60)+ _make_lags_for_hour(offset.n / (60 * 60)))else:raise Exception("invalid frequency")# flatten lags list and filterlags = [int(lag) for sub_list in lags for lag in sub_list if 7 < lag <= lag_ub]lags = list(range(1, num_default_lags + 1)) + sorted(list(set(lags)))return lags[:num_lags]
第一部分,生成以middle为中心,以delta为半径的区间[middle-delta,middle+delta] ,这很好理解,比如一周的周期是7天,周期大小在7天附近波动很正常。

第二部分,对于年月日时分秒这些不同的采样频率,采用不同的具体的函数来确定lags,其中有一个参数num_cycle,进一步利用了周期性,我们考虑间隔1、2、3、…num个周期的时间点之间的联系

原理类似于这张图,这种周期性的重复性体现在邻近的多个周期上
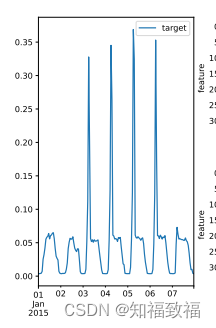
lag的用途
计算各类窗口大小
计算采样窗口大小
window_size = estimator.context_length + max(estimator.lags_seq) + estimator.prediction_length# Here we make a window slightly bigger so that instance sampler can sample from each window# An alternative is to have exact size and use different instance sampler (e.g. ValidationSplitSampler)
window_size = 10 * window_size
# We change ValidationSplitSampler to add min_pastestimator.validation_sampler = ValidationSplitSampler(min_past=estimator.context_length + max(estimator.lags_seq),min_future=estimator.prediction_length,)- 构建静态特征
lags = lagged_sequence_values(self.lags_seq, prior_input, input, dim=-1)#构建一个包含给定序列的滞后值的数组static_feat = torch.cat((loc.abs().log1p(), scale.log()), dim=-1)
expanded_static_feat = unsqueeze_expand(static_feat, dim=-2, size=lags.shape[-2]
)return torch.cat((lags, expanded_static_feat, time_feat), dim=-1), loc, scale
数据集准备过程
对每个数据集采样,window_size=13500,也挺离谱的
train_data, val_data = [], []for name in TRAIN_DATASET_NAMES:new_data = create_sliding_window_dataset(name, window_size)train_data.append(new_data)new_data = create_sliding_window_dataset(name, window_size, is_train=False)val_data.append(new_data)
采样的具体过程,这里有个问题,样本数量很小的数据集,实际采样窗口大小小于设定的window_size,后续会如何对齐呢?
文章设置单变量预测单变量,所以样本进行了通道分离,同一样本的不同特征被采样为不同的样本
def create_sliding_window_dataset(name, window_size, is_train=True):#划分非重叠的滑动窗口数据集,window_size是对数据集采样的数量,对每个数据集只取前windowsize个样本# Splits each time series into non-overlapping sliding windowsglobal_id = 0freq = get_dataset(name, path=dataset_path).metadata.freq#从数据集中获取时间频率data = ListDataset([], freq=freq)#创建空数据集dataset = get_dataset(name, path=dataset_path).train if is_train else get_dataset(name, path=dataset_path).test#获取原始数据集for x in dataset:windows = []#划分滑动窗口#target:滑动窗口的目标值#start:滑动窗口的起始位置#item_id,唯一标识符#feat_static_cat:静态特征数组for i in range(0, len(x['target']), window_size):windows.append({'target': x['target'][i:i+window_size],'start': x['start'] + i,'item_id': str(global_id),'feat_static_cat': np.array([0]),})global_id += 1data += ListDataset(windows, freq=freq)return data
合并数据集
# Here weights are proportional to the number of time series (=sliding windows)weights = [len(x) for x in train_data]# Here weights are proportinal to the number of individual points in all time series# weights = [sum([len(x["target"]) for x in d]) for d in train_data]train_data = CombinedDataset(train_data, weights=weights)val_data = CombinedDataset(val_data, weights=weights)
class CombinedDataset:def __init__(self, datasets, seed=None, weights=None):self._seed = seedself._datasets = datasetsself._weights = weightsn_datasets = len(datasets)if weights is None:#如果未提供权重,默认平均分配权重self._weights = [1 / n_datasets] * n_datasetsdef __iter__(self):return CombinedDatasetIterator(self._datasets, self._seed, self._weights)def __len__(self):return sum([len(ds) for ds in self._datasets])
网络结构
lagllama
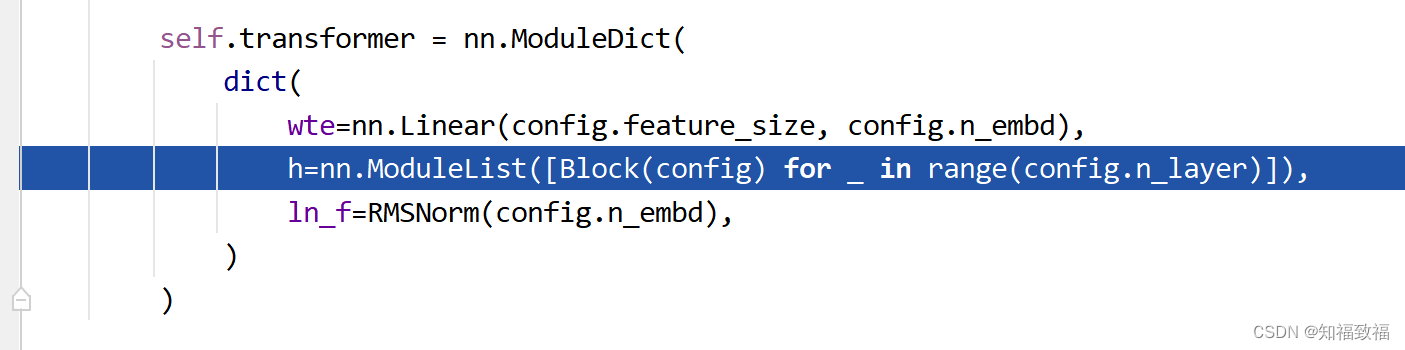
class LagLlamaModel(nn.Module):def __init__(self,max_context_length: int,scaling: str,input_size: int,n_layer: int,n_embd: int,n_head: int,lags_seq: List[int],rope_scaling=None,distr_output=StudentTOutput(),num_parallel_samples: int = 100,) -> None:super().__init__()self.lags_seq = lags_seqconfig = LTSMConfig(n_layer=n_layer,n_embd=n_embd,n_head=n_head,block_size=max_context_length,feature_size=input_size * (len(self.lags_seq)) + 2 * input_size + 6,rope_scaling=rope_scaling,)self.num_parallel_samples = num_parallel_samplesif scaling == "mean":self.scaler = MeanScaler(keepdim=True, dim=1)elif scaling == "std":self.scaler = StdScaler(keepdim=True, dim=1)else:self.scaler = NOPScaler(keepdim=True, dim=1)self.distr_output = distr_outputself.param_proj = self.distr_output.get_args_proj(config.n_embd)self.transformer = nn.ModuleDict(dict(wte=nn.Linear(config.feature_size, config.n_embd),h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]),ln_f=RMSNorm(config.n_embd),))
主要是transformer里面首先是一个线性层,然后加了n_layer个Block,最后是RMSNorm,接下来解析Block的代码
Block
class Block(nn.Module):def __init__(self, config: LTSMConfig) -> None:super().__init__()self.rms_1 = RMSNorm(config.n_embd)self.attn = CausalSelfAttention(config)self.rms_2 = RMSNorm(config.n_embd)self.mlp = MLP(config)self.y_cache = Nonedef forward(self, x: torch.Tensor, is_test: bool) -> torch.Tensor:if is_test and self.y_cache is not None:# Only use the most recent one, rest is in cachex = x[:, -1:]x = x + self.attn(self.rms_1(x), is_test)y = x + self.mlp(self.rms_2(x))if is_test:if self.y_cache is None:self.y_cache = y # Build cacheelse:self.y_cache = torch.cat([self.y_cache, y], dim=1)[:, 1:] # Update cachereturn y代码看到这里不太想继续看了,太多glunoTS库里面的函数了,我完全不熟悉这个库,看起来太痛苦了,还有很多的困惑,最大的困惑就是数据是怎么对齐的,怎么输入到Llama里面的,慢慢看吧
其他
来源