手机网站自适应网上培训机构
目录
- DAY 18 推断聚类后簇的类型
- 1.推断簇含义的2个思路:先选特征和后选特征
- 2.通过可视化图形借助ai定义簇的含义
- 3.科研逻辑闭环:通过精度判断特征工程价值
- 作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
DAY 18 推断聚类后簇的类型
聚类后的分析:推断簇的类型
import seaborn as sns
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
import numpy as np
import warnings
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from catboost import CatBoostClassifier
from sklearn.ensemble import RandomForestClassifier
import lightgbm as lgb
import xgboost as xgb
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
import time
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedata = pd.read_csv(r'data.csv')list_discrete = data.select_dtypes(include=['object']).columns.tolist()home_ownership_mapping = {'Own Home': 1, 'Rent': 2,'Have Mortgage': 3, 'Home Mortgage': 4}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)years_in_job_mapping = {'< 1 year': 1, '1 year': 2, '2 years': 3, '3 years': 4, '4 years': 5,'5 years': 6, '6 years': 7, '7 years': 8, '8 years': 9, '9 years': 10, '10+ years': 11}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv(r'data.csv')
list_new = []
for i in data.columns:if i not in data2.columns:list_new.append(i)
for i in list_new:data[i] = data[i].astype(int)term_mapping = {'Short Term': 0, 'Long Term': 1}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True)list_continuous = data.select_dtypes(include=['int64', 'float64']).columns.tolist()for i in list_continuous:median_value = data[i].median()data[i] = data[i].fillna(median_value)X = data.drop(['Credit Default'], axis=1)
Y = data['Credit Default']scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as pltk_range = range(2, 11)
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_)silhouette = silhouette_score(X_scaled, kmeans_labels)silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels)ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels)db_scores.append(db)print(f'k = {k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}')selected_k = 3kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labelspca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1],hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k = {selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()print(f"KMeans Cluster labels (k = {selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())k = 2, 惯性: 224921.38, 轮廓系数: 0.723, CH 指数: 252.64, DB 指数: 0.355
k = 3, 惯性: 210919.39, 轮廓系数: 0.320, CH 指数: 383.53, DB 指数: 2.446
k = 4, 惯性: 204637.65, 轮廓系数: 0.087, CH 指数: 340.21, DB 指数: 2.315
k = 5, 惯性: 198854.98, 轮廓系数: 0.106, CH 指数: 317.03, DB 指数: 2.232
k = 6, 惯性: 191274.31, 轮廓系数: 0.112, CH 指数: 323.04, DB 指数: 1.921
k = 7, 惯性: 183472.98, 轮廓系数: 0.121, CH 指数: 333.71, DB 指数: 1.750
k = 8, 惯性: 174533.93, 轮廓系数: 0.131, CH 指数: 355.46, DB 指数: 2.089
k = 9, 惯性: 167022.49, 轮廓系数: 0.133, CH 指数: 367.09, DB 指数: 1.862
k = 10, 惯性: 163353.82, 轮廓系数: 0.097, CH 指数: 352.27, DB 指数: 1.838
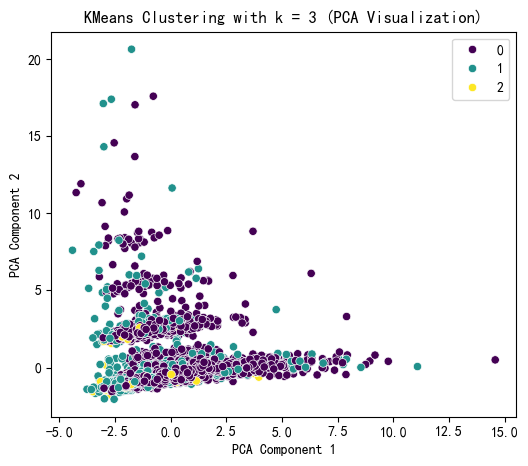
KMeans Cluster labels (k = 3) added to X:
KMeans_Cluster
0 5953
1 1451
2 96
Name: count, dtype: int64
X.columnsIndex(['Id', 'Home Ownership', 'Annual Income', 'Years in current job','Tax Liens', 'Number of Open Accounts', 'Years of Credit History','Maximum Open Credit', 'Number of Credit Problems','Months since last delinquent', 'Bankruptcies', 'Long Term','Current Loan Amount', 'Current Credit Balance', 'Monthly Debt','Credit Score', 'Purpose_business loan', 'Purpose_buy a car','Purpose_buy house', 'Purpose_debt consolidation','Purpose_educational expenses', 'Purpose_home improvements','Purpose_major purchase', 'Purpose_medical bills', 'Purpose_moving','Purpose_other', 'Purpose_renewable energy', 'Purpose_small business','Purpose_take a trip', 'Purpose_vacation', 'Purpose_wedding','KMeans_Cluster'],dtype='object')
1.推断簇含义的2个思路:先选特征和后选特征
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import shapx1 = X.drop('KMeans_Cluster', axis=1)
y1 = X['KMeans_Cluster']
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(x1, y1)shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1)shap_values.shape(7500, 31, 3)
2.通过可视化图形借助ai定义簇的含义
print('SHAP 特征重要性条形图')
shap.summary_plot(shap_values[:, :, 0], x1, plot_type='bar', show=False)
plt.title('SHAP Feature Importance (Bar Plot)')
plt.show()SHAP 特征重要性条形图
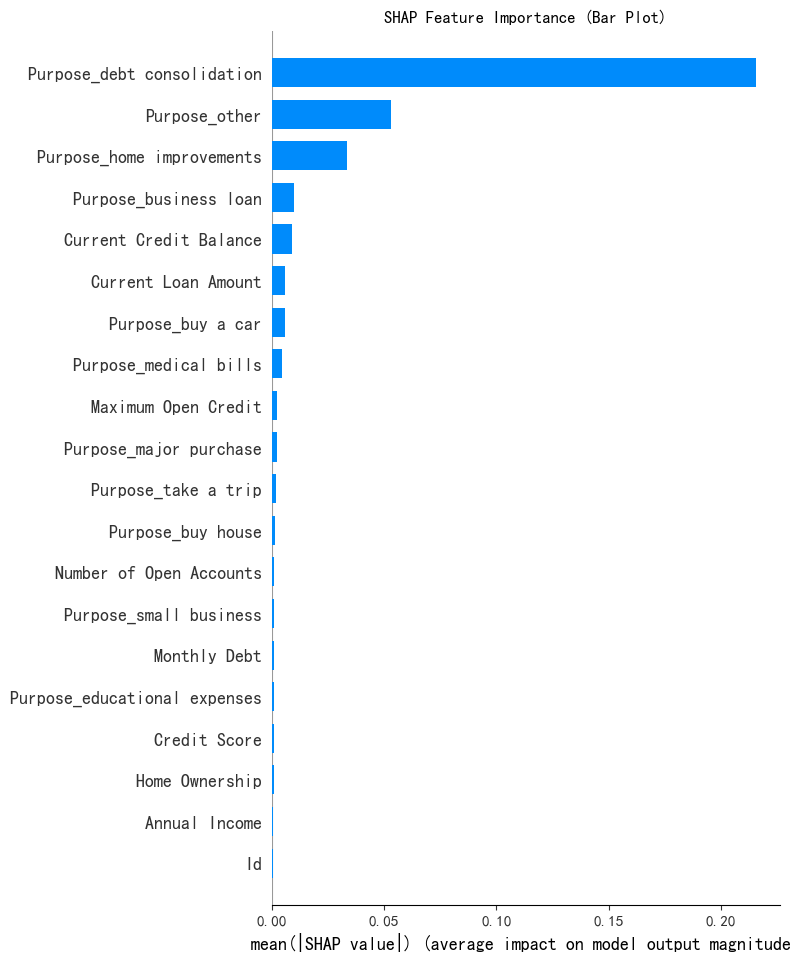
selected_features = ['Purpose_debt consolidation', 'Purpose_other','Purpose_home improvements', 'Purpose_business loan']for feature in selected_features:unique_count = X[feature].nunique()print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10:print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')Purpose_debt consolidation 的唯一值数量: 2
Purpose_debt consolidation 可能是离散型变量
Purpose_other 的唯一值数量: 2
Purpose_other 可能是离散型变量
Purpose_home improvements 的唯一值数量: 2
Purpose_home improvements 可能是离散型变量
Purpose_business loan 的唯一值数量: 2
Purpose_business loan 可能是离散型变量
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()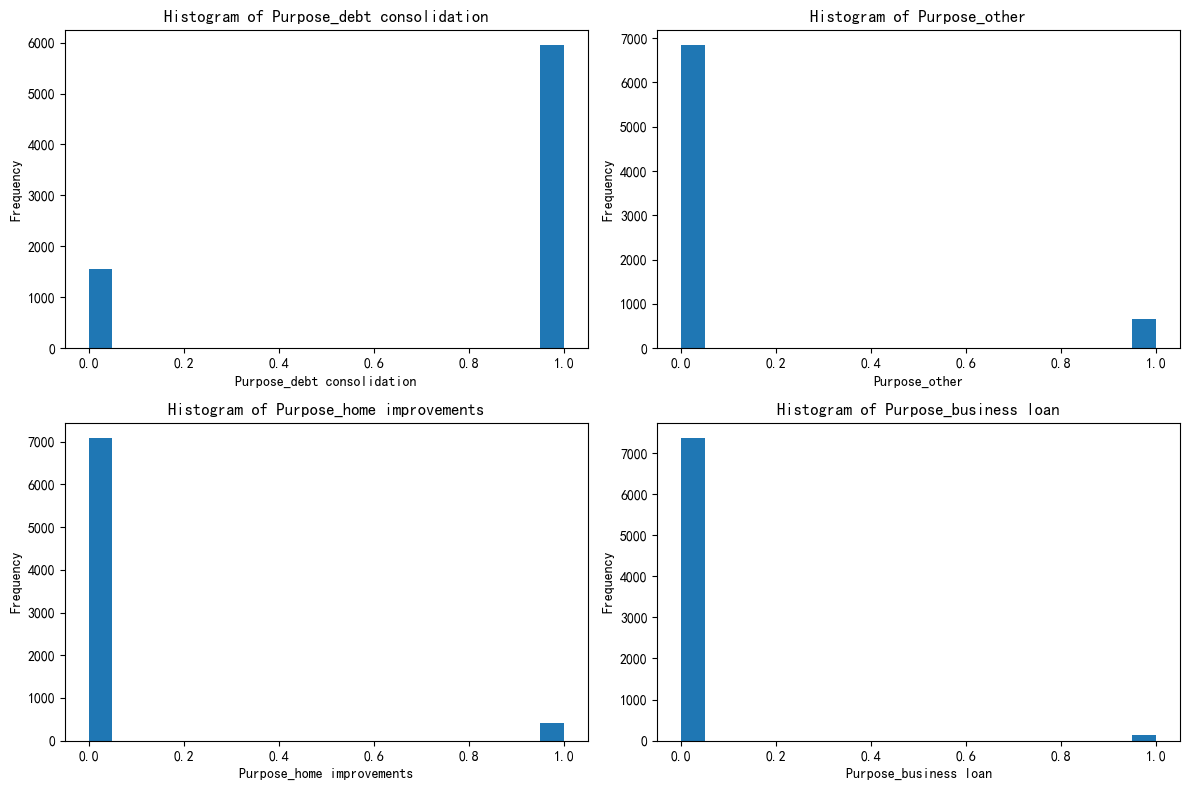
X[['KMeans_Cluster']].value_counts()KMeans_Cluster
0 5953
1 1451
2 96
Name: count, dtype: int64
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
X_cluster2 = X[X['KMeans_Cluster'] == 2]import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()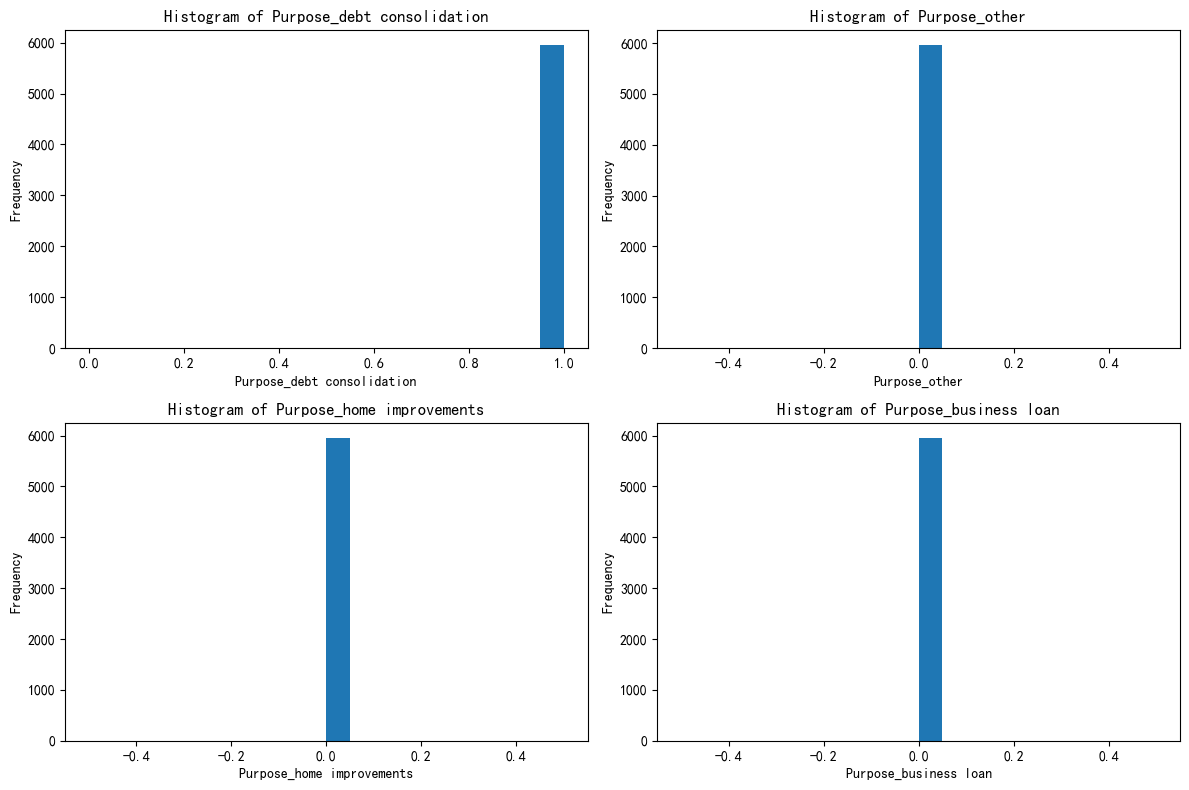
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster1[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()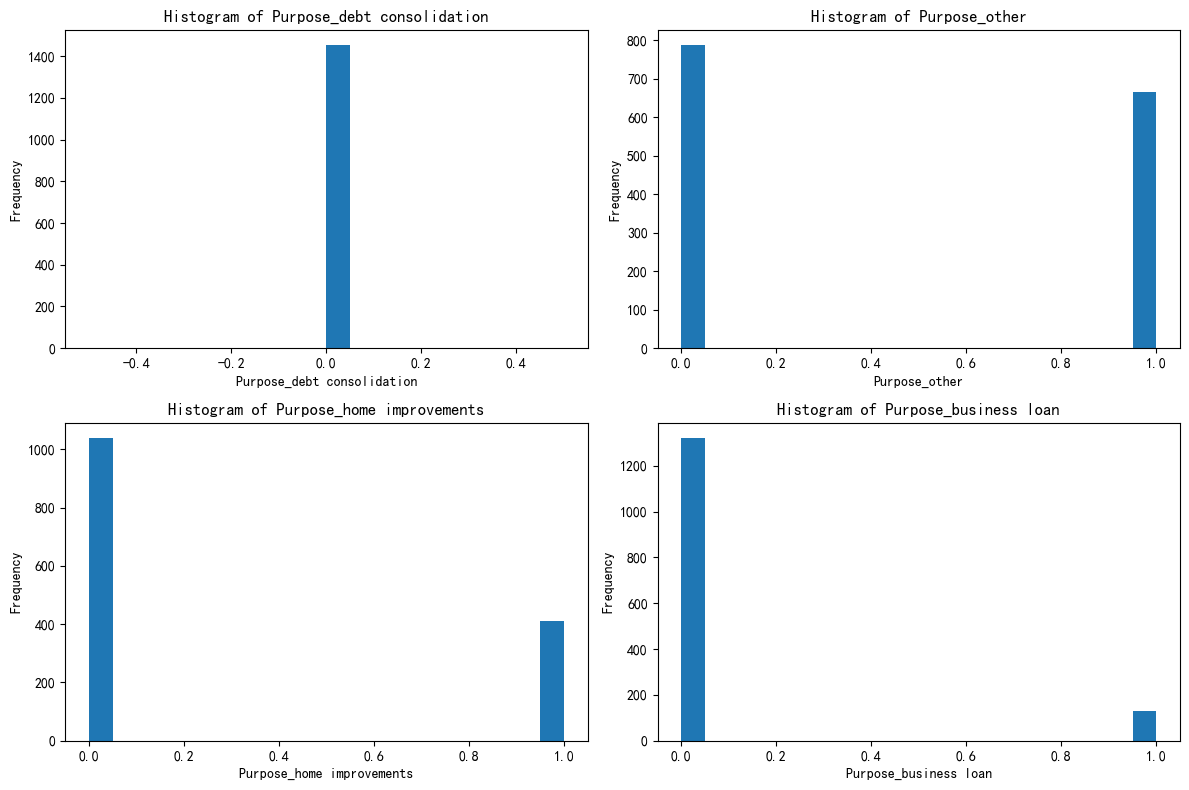
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster2[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()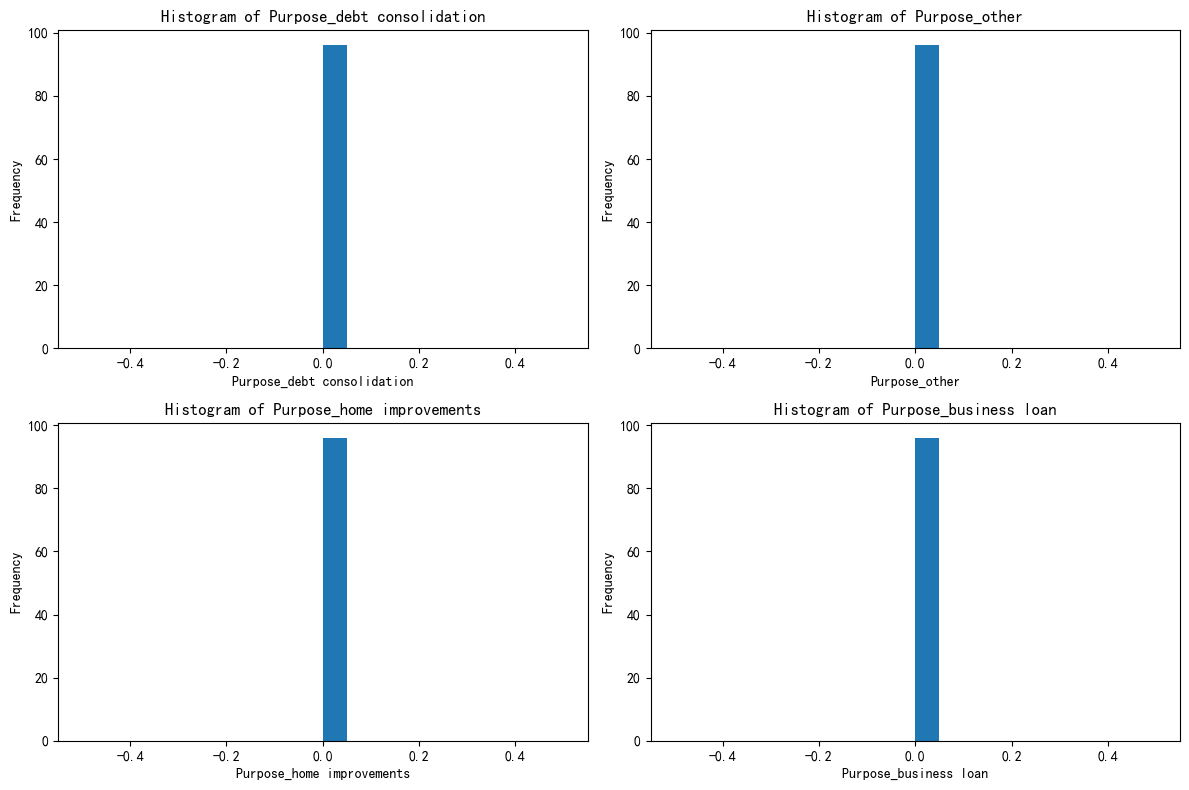
3.科研逻辑闭环:通过精度判断特征工程价值
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
import matplotlib.pyplot as plt
import time
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
import xgboost as xgb
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from catboost import CatBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, confusion_matrix
import warnings
import numpy as np
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import seaborn as sns
from sklearn.model_selection import train_test_split
import pandas as pd
warnings.filterwarnings('ignore')plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedata = pd.read_csv(r'heart.csv')X = data.drop(['target'], axis=1)
Y = data['target']scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as pltk_range = range(2, 11)
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_)silhouette = silhouette_score(X_scaled, kmeans_labels)silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels)ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels)db_scores.append(db)print(f'k = {k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}')selected_k = 3kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labelspca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1],hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k = {selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()print(f"KMeans Cluster labels (k = {selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())k = 2, 惯性: 3331.64, 轮廓系数: 0.166, CH 指数: 54.87, DB 指数: 2.209
k = 3, 惯性: 3087.69, 轮廓系数: 0.112, CH 指数: 41.36, DB 指数: 2.544
k = 4, 惯性: 2892.52, 轮廓系数: 0.118, CH 指数: 36.06, DB 指数: 2.175
k = 5, 惯性: 2814.65, 轮廓系数: 0.094, CH 指数: 29.76, DB 指数: 2.386
k = 6, 惯性: 2673.22, 轮廓系数: 0.095, CH 指数: 28.13, DB 指数: 2.377
k = 7, 惯性: 2596.68, 轮廓系数: 0.088, CH 指数: 25.50, DB 指数: 2.290
k = 8, 惯性: 2464.39, 轮廓系数: 0.115, CH 指数: 25.22, DB 指数: 2.136
k = 9, 惯性: 2415.63, 轮廓系数: 0.105, CH 指数: 23.18, DB 指数: 2.133
k = 10, 惯性: 2337.41, 轮廓系数: 0.111, CH 指数: 22.31, DB 指数: 2.056
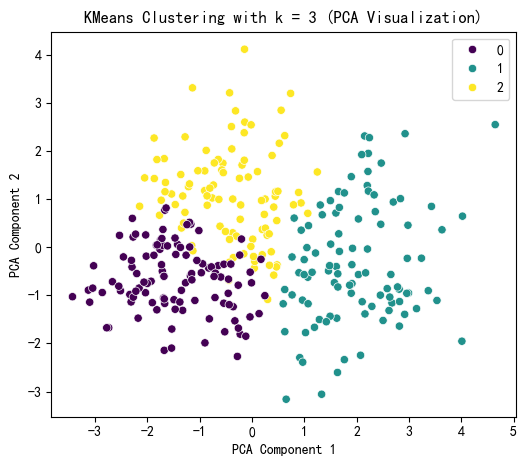
KMeans Cluster labels (k = 3) added to X:
KMeans_Cluster
0 108
1 98
2 97
Name: count, dtype: int64
X.columnsIndex(['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach','exang', 'oldpeak', 'slope', 'ca', 'thal', 'KMeans_Cluster'],dtype='object')
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import shapx1 = X.drop('KMeans_Cluster', axis=1)
y1 = X['KMeans_Cluster']
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(x1, y1)shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1)shap_values.shape(303, 13, 3)
print('SHAP 特征重要性条形图')
shap.summary_plot(shap_values[:, :, 0], x1, plot_type='bar', show=False)
plt.title('SHAP Feature Importance (Bar Plot)')
plt.show()SHAP 特征重要性条形图
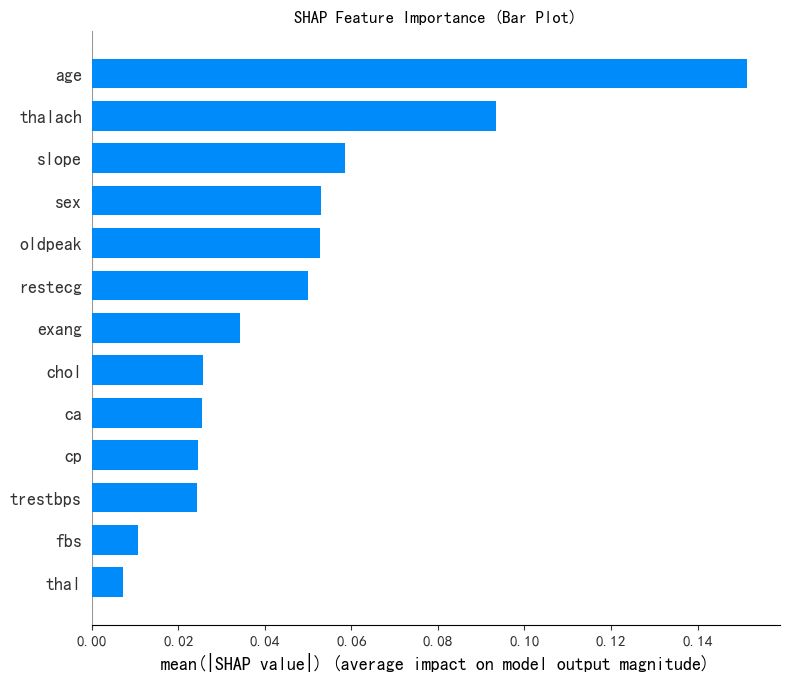
selected_features = ['slope', 'sex', 'restecg', 'exang']for feature in selected_features:unique_count = X[feature].nunique()print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10:print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')slope 的唯一值数量: 3
slope 可能是离散型变量
sex 的唯一值数量: 2
sex 可能是离散型变量
restecg 的唯一值数量: 3
restecg 可能是离散型变量
exang 的唯一值数量: 2
exang 可能是离散型变量
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()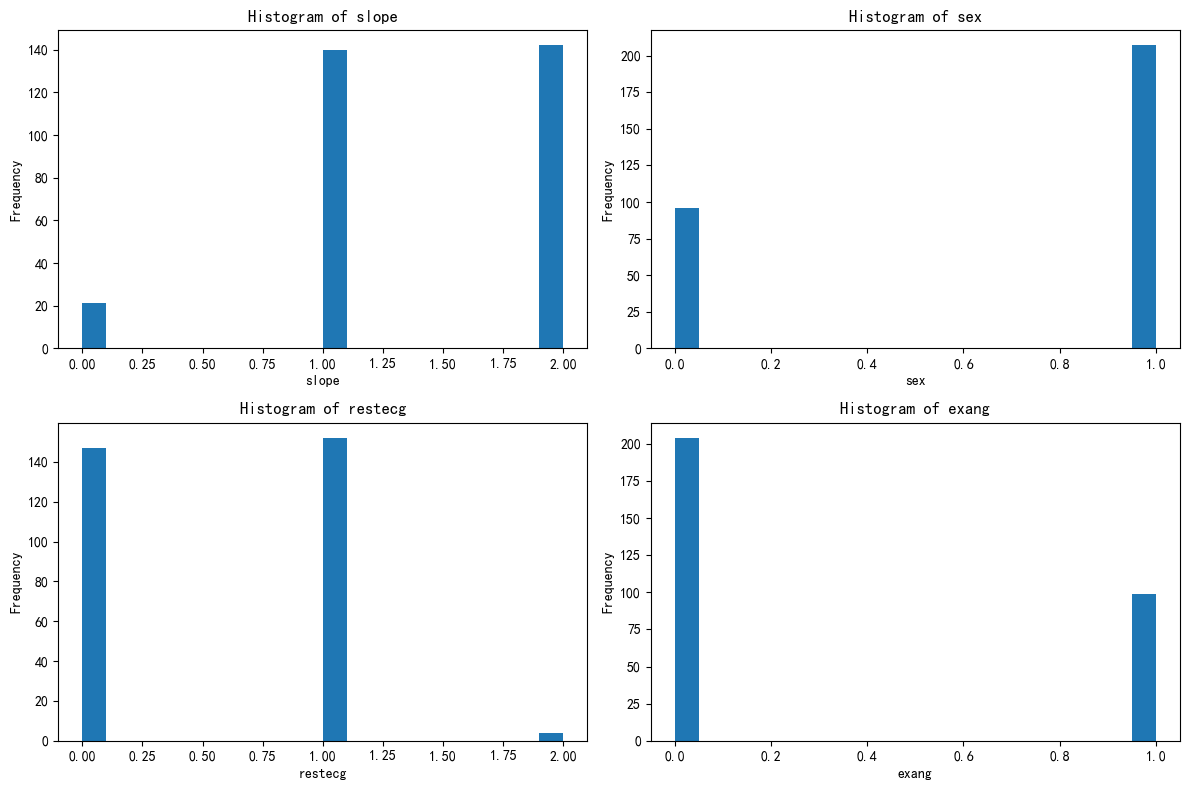
X[['KMeans_Cluster']].value_counts()KMeans_Cluster
0 108
1 98
2 97
Name: count, dtype: int64
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
X_cluster2 = X[X['KMeans_Cluster'] == 2]import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()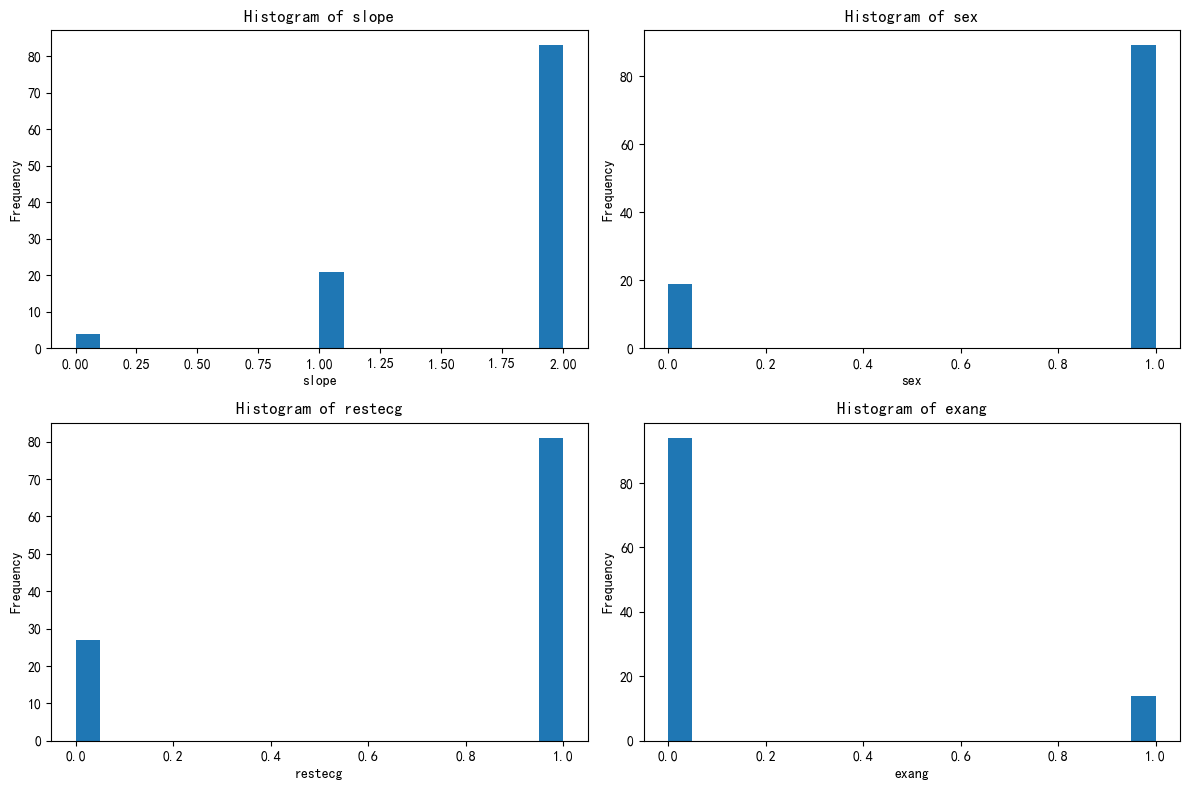
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster1[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()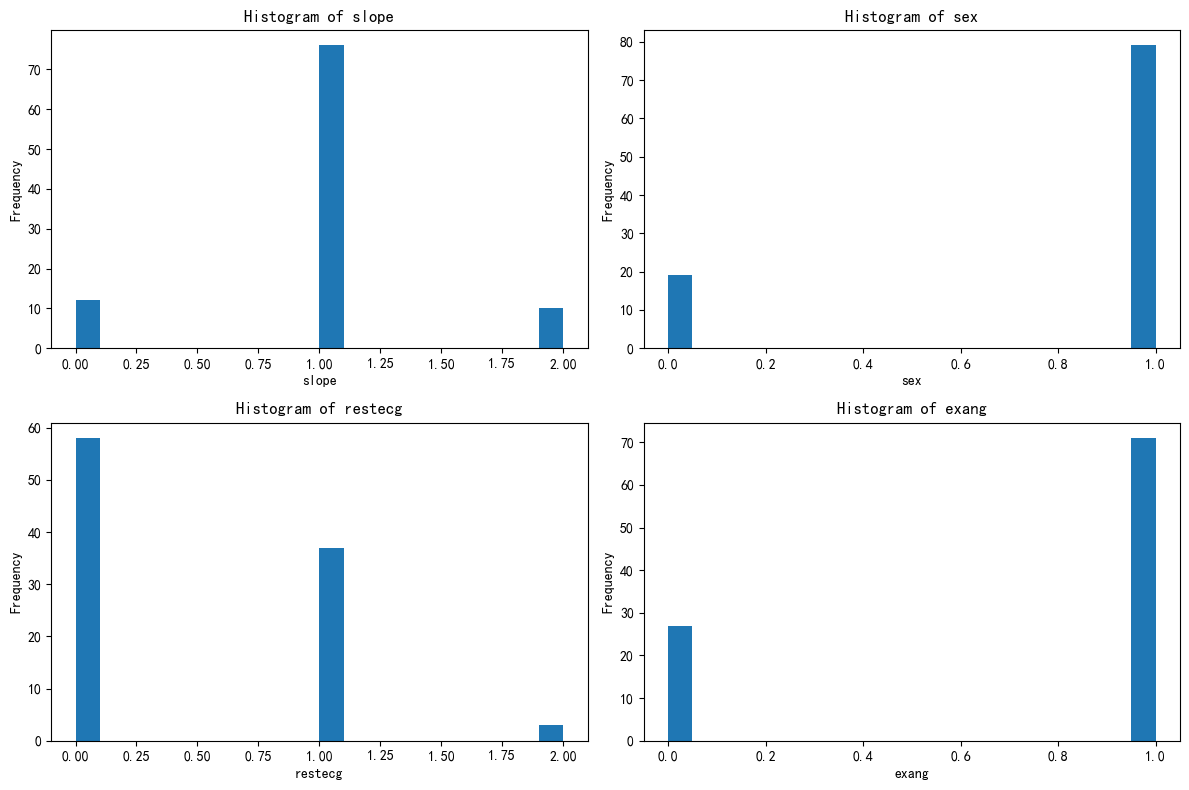
import matplotlib.pyplot as pltfig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster2[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()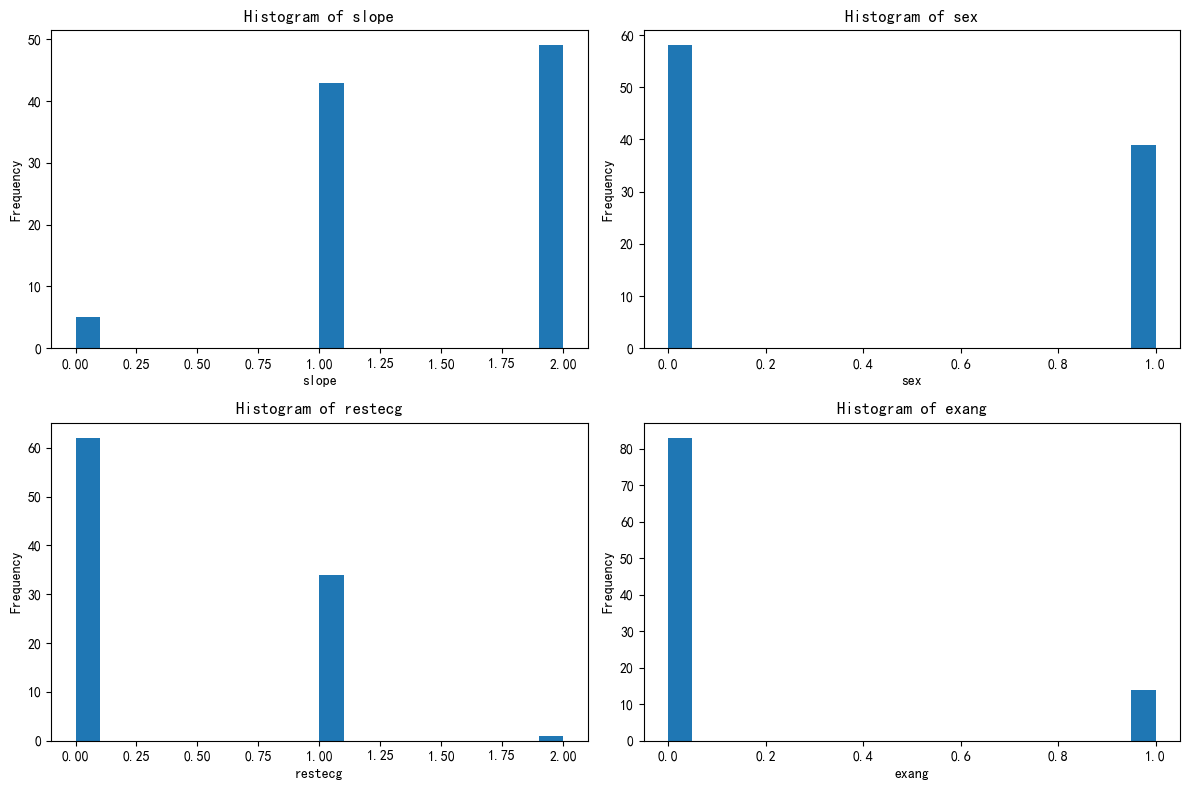
@浙大疏锦行