新疆建设云网站怎么查询证书芜湖seo
一、引言
在信息爆炸的时代,假新闻的传播对社会产生了诸多负面影响。如何快速、准确地识别假新闻成为了重要的研究课题。本文将对比传统机器学习算法(朴素贝叶斯)与深度学习模型(LSTM)在假新闻检测任务中的性能表现,包括准确率、训练时间和预测时间等指标,并通过代码实现完整的建模流程。
二、数据准备与预处理
2.1 数据读取与标签设置
本文使用的数据集包含真实新闻(True.csv)和虚假新闻(Fake.csv),通过pandas读取后为两类数据添加标签(1 代表真新闻,0 代表假新闻),并合并为完整数据集:
true_df = pd.read_csv('True.csv')
fake_df = pd.read_csv('Fake.csv')
true_df['label'] = 1
fake_df['label'] = 0
combined_df = pd.concat([true_df, fake_df], axis=0)
2.2 文本清洗
通过正则表达式去除非字母数字字符,并将文本转换为小写,提升模型输入质量:
def clean_text(text):text = re.sub(r'[^\w\s]', '', text).lower()return text
combined_df['text'] = combined_df['text'].apply(clean_text)
2.3 数据集划分
按照 8:2 的比例将数据划分为训练集和测试集,确保模型评估的客观性:
X = combined_df['text']
y = combined_df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
三、模型构建与训练
3.1 朴素贝叶斯模型(传统机器学习)
3.1.1 特征工程:TF-IDF 向量化
通过 TF-IDF(词频 - 逆文档频率)将文本转换为数值特征,捕捉词语在文档中的重要性:
vectorizer = TfidfVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
3.1.2 模型训练与评估
使用多项式朴素贝叶斯分类器进行训练,并计算训练时间、预测时间和准确率:
clf = MultinomialNB()
clf.fit(X_train_vec, y_train)
y_pred_bayes = clf.predict(X_test_vec)
accuracy_bayes = accuracy_score(y_test, y_pred_bayes)3.2 LSTM 模型(深度学习)
3.2.1 文本向量化:Tokenizer 与序列填充
通过Tokenizer将文本转换为整数序列,并使用固定长度(500)填充序列,适配神经网络输入:
max_words = 10000
max_sequence_length = 500
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(X_train)
X_train_seq = tokenizer.texts_to_sequences(X_train)
X_train_pad = pad_sequences(X_train_seq, maxlen=max_sequence_length)
3.2.2 模型架构设计
构建包含嵌入层(Embedding)、两层 LSTM 层和 Dropout 正则化的神经网络,用于捕捉文本序列中的语义特征:
model = Sequential([Embedding(max_words, 100, input_length=max_sequence_length),LSTM(128, return_sequences=True),Dropout(0.5),LSTM(64),Dropout(0.5),Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
3.2.3 训练过程优化
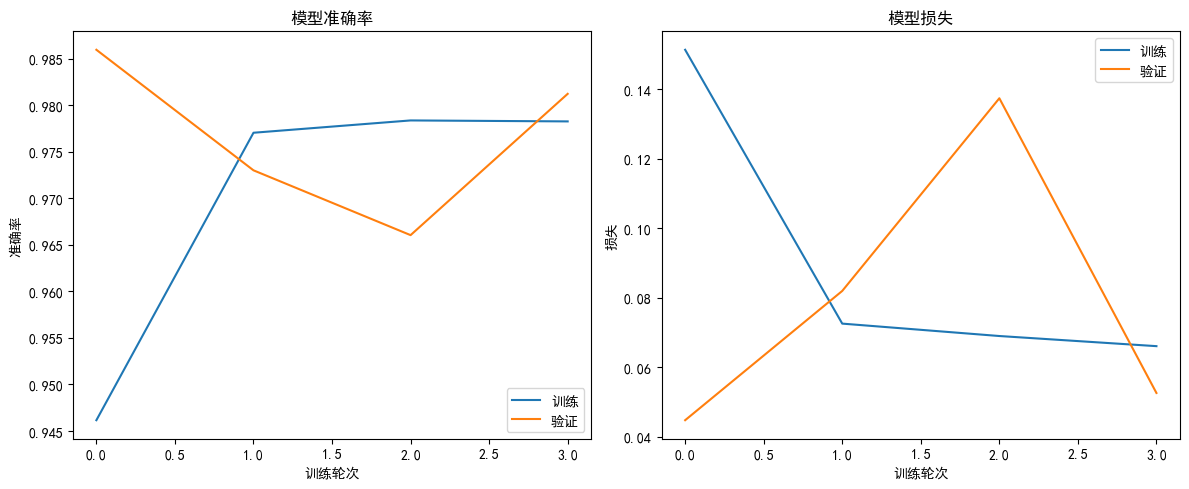
使用早停法(Early Stopping)防止过拟合,自动保存最优权重:
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
history = model.fit(X_train_pad, y_train, epochs=10, batch_size=64, validation_split=0.2, callbacks=[early_stopping])
四、结果对比与分析
4.1 性能指标对比
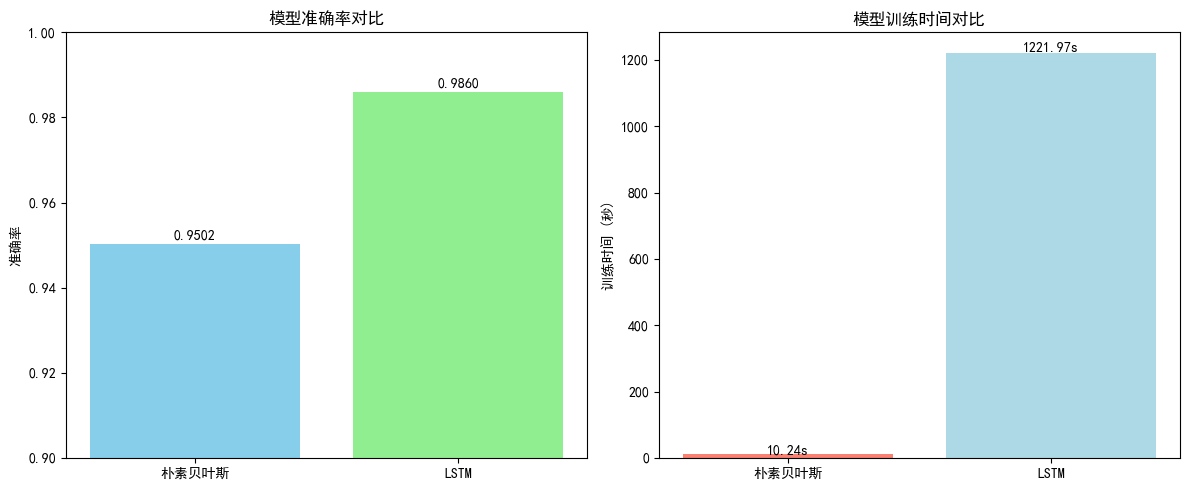
4.2 混淆矩阵
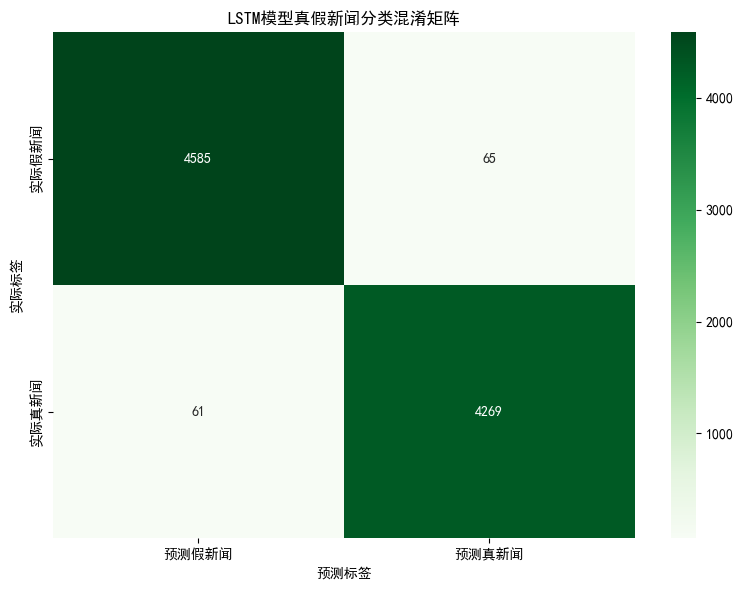
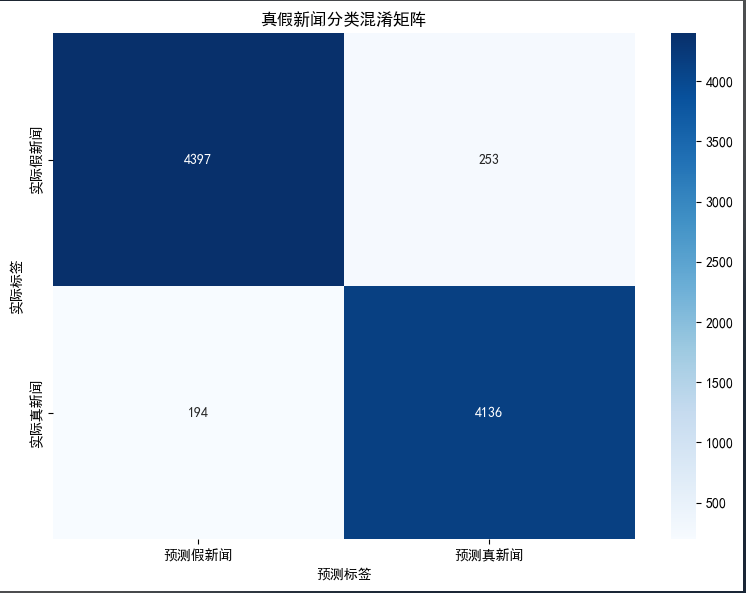
4.2 训练历史曲线
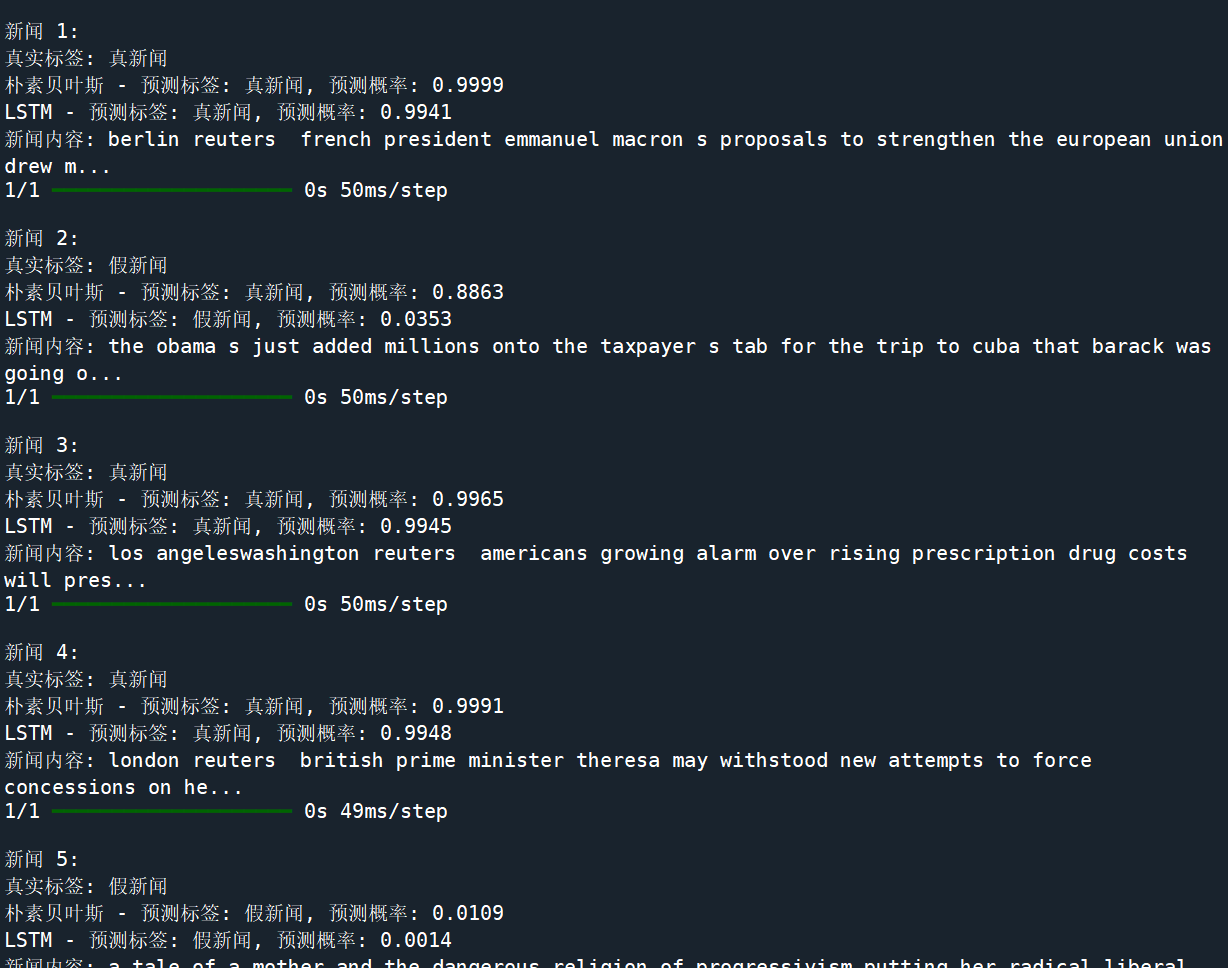
五、随机样本预测示例
# 随机选择5条新闻对比预测结果
np.random.seed(42)
random_indices = np.random.choice(len(X_test), 5, replace=False)
for i, idx in enumerate(random_indices):text = X_test.iloc[idx]true_label = y_test.iloc[idx]# 朴素贝叶斯与LSTM预测逻辑...print(f"新闻 {i+1}: 真实标签 {true_label}, 贝叶斯预测 {pred_bayes}, LSTM预测 {pred_lstm}")
六、总结与展望
朴素贝叶斯:优点是训练速度快、计算资源需求低,适合小规模数据或实时预测场景。
LSTM:在准确率上有优势,能更好捕捉文本语义特征,但需要更高的计算成本。
改进方向:可尝试优化 LSTM 参数(如层数、神经元数量)、使用预训练词向量(如 GloVe)或结合注意力机制进一步提升性能。