做网站投诉要钱吗互联网产品运营推广方案
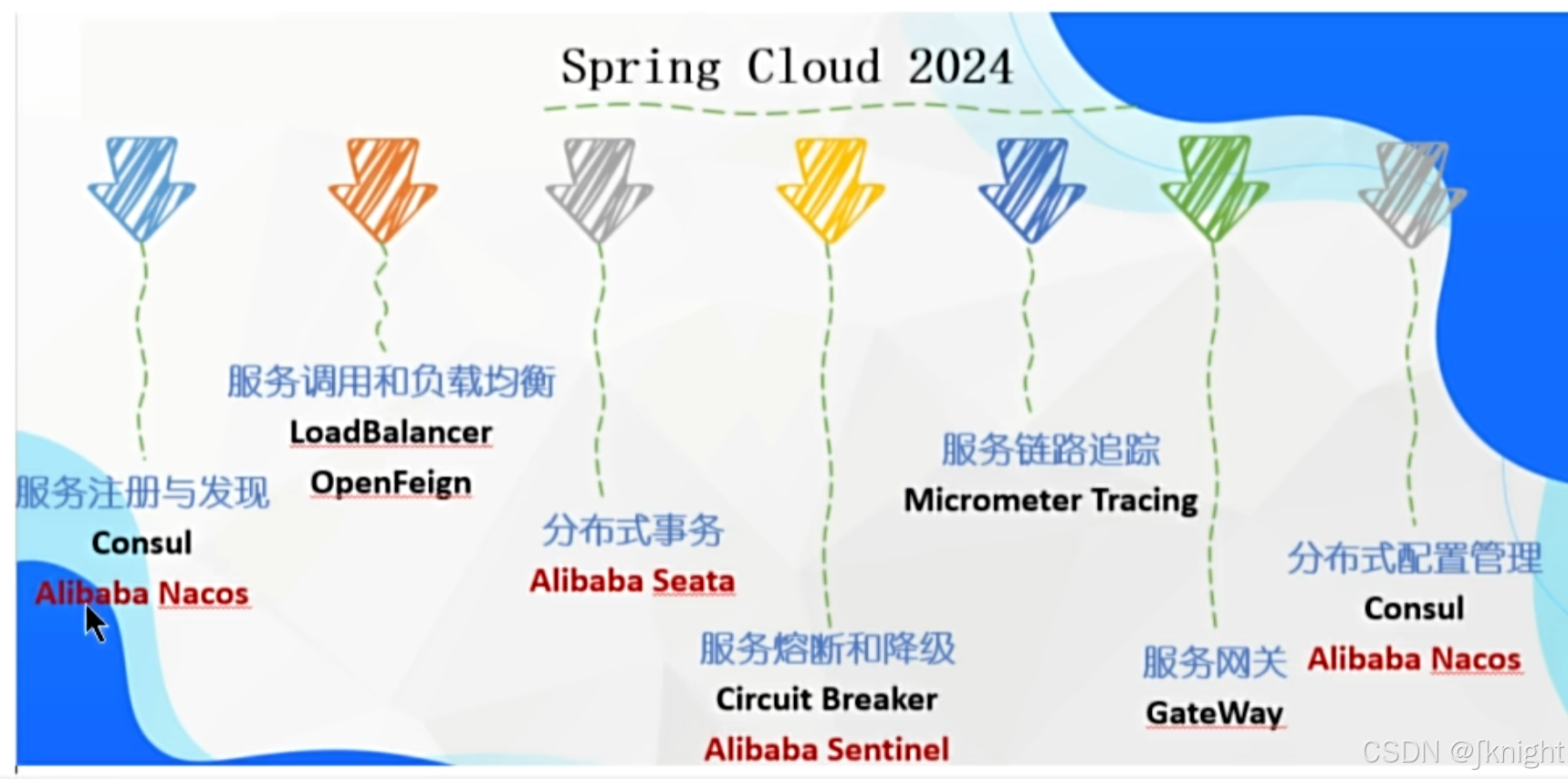
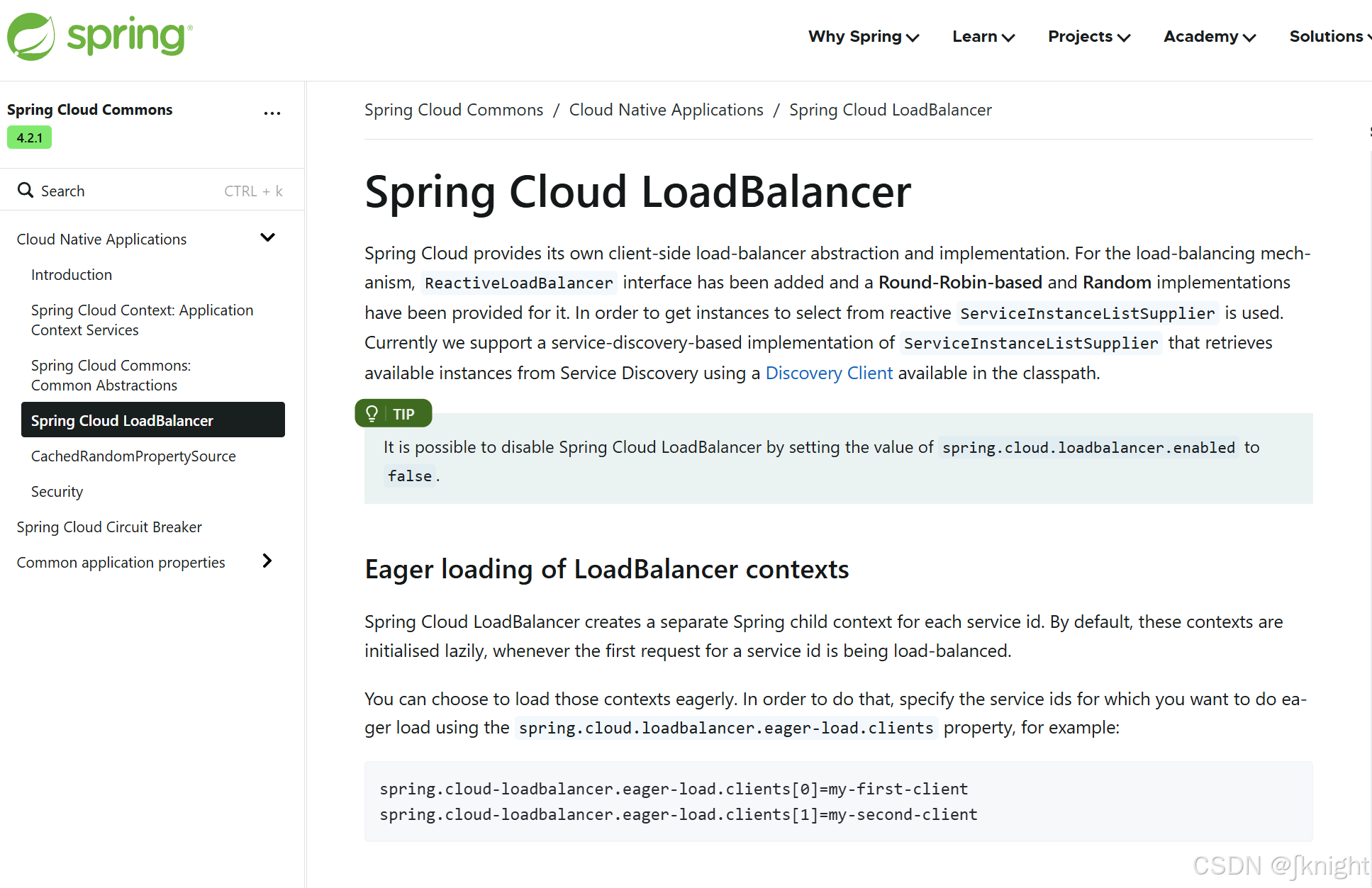
一、Consul服务注册和发现

为什么引入注册中心
微服务所在的IP地址和端口号硬编码到订单微服务中,会存在非常多的问题
(1)如果订单微服务和支付微服务的IP地址或者端口号发生了变化,则支付微服务将变得不可用,需要同步修改订单微服务中调用支付微服务的IP地址和端口号。
(2)如果系统中提供了多个订单微服务和支付微服务,则无法实现微服务的负载均衡功能。
(3)如果系统需要支持更高的并发,需要部署更多的订单微服务和支付微服务,硬编码订单微服务则后续的维护会变得异常复杂。
所以,在微服务开发的过程中,需要引入服务治理功能,实现微服务之间的动态注册与发现,从此刻开始我们正式进入SpringCloud实战
consul是什么?
怎么使用?
安装后出现exe文件,运行后,打开cmd窗口,执行consul agent -dev
再打开localhost:8500会出现下面页面
服务提供者8001集成
修改pom
<!--SpringCloud consul discovery --> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId><exclusions><exclusion><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId></exclusion></exclusions> </dependency>
修改yml
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
启动类添加注解
@EnableDiscoveryClient
此时运行项目会发现localhost:8500中多了一个项目

服务消费者80集成
和服务提供者8001类似,这里要注意
controller层的
public static final String PaymentSrv_URL="http://cloud-payment-service";URL写成8001的项目名,就是上面图片中的名字
但是这里直接运行会报错
2025-04-07T15:57:50.880+08:00 ERROR 22004 --- [p-nio-80-exec-5] c.a.cloud.exp.GlobalExceptionHandler : 全局异常信息:I/O error on GET request for "http://cloud-payment-service/pay/get/1": cloud-payment-service
原因
服务地址解析
在微服务架构中,通常会用服务名(像cloud-payment-service)来标识服务,而非具体的 IP 地址和端口号。没有@LoadBalanced注解时,RestTemplate会把cloud-payment-service当作普通的主机名处理,无法将其解析为具体服务实例的 IP 地址和端口号,从而导致请求失败。
当添加@LoadBalanced注解后,RestTemplate会与服务注册中心(如 Eureka、Consul)协作,从注册中心获取cloud-payment-service对应的所有服务实例列表,然后从列表里挑选一个合适的实例来发送请求。
负载均衡
在实际生产环境中,一个服务往往会有多个实例来处理高并发请求。@LoadBalanced注解会为RestTemplate集成负载均衡器(如 Ribbon),负载均衡器会按照特定的算法(例如轮询、随机等)从服务实例列表里选择一个实例处理请求。
要是没有@LoadBalanced注解,请求就无法被正确分发到可用的服务实例上,可能会因为请求的实例不可用而失败。添加该注解后,负载均衡器会保证请求被分发到健康的实例上,从而提升请求成功的概率。
解决方法,在消费者的config中添加@LoadBalanced注解
@Configurationpublic class RestTemplateConfig
{@Bean @LoadBalancedpublic RestTemplate restTemplate(){return new RestTemplate();}
}
此时的8500端口
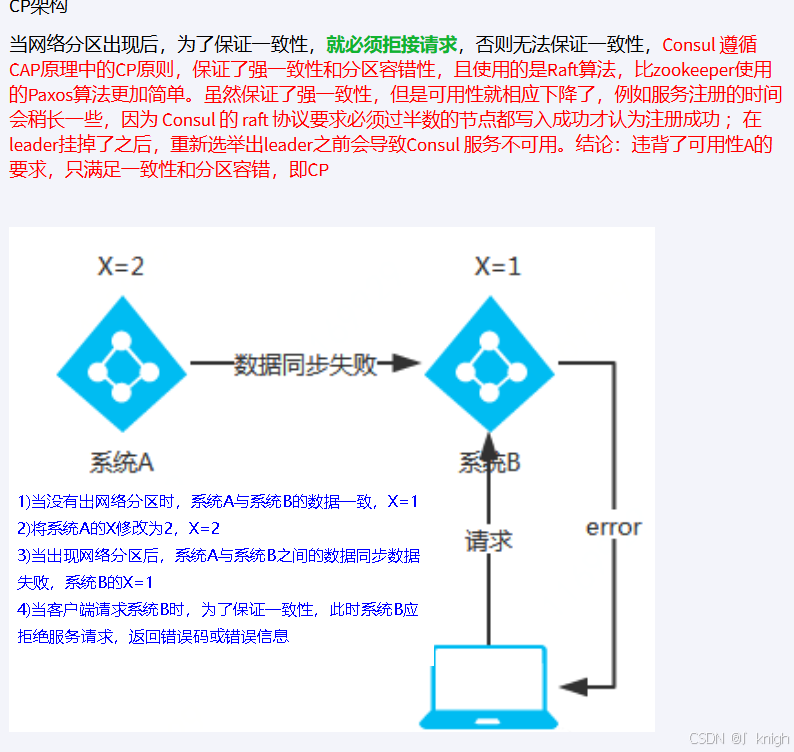
注册中心的异同
AP
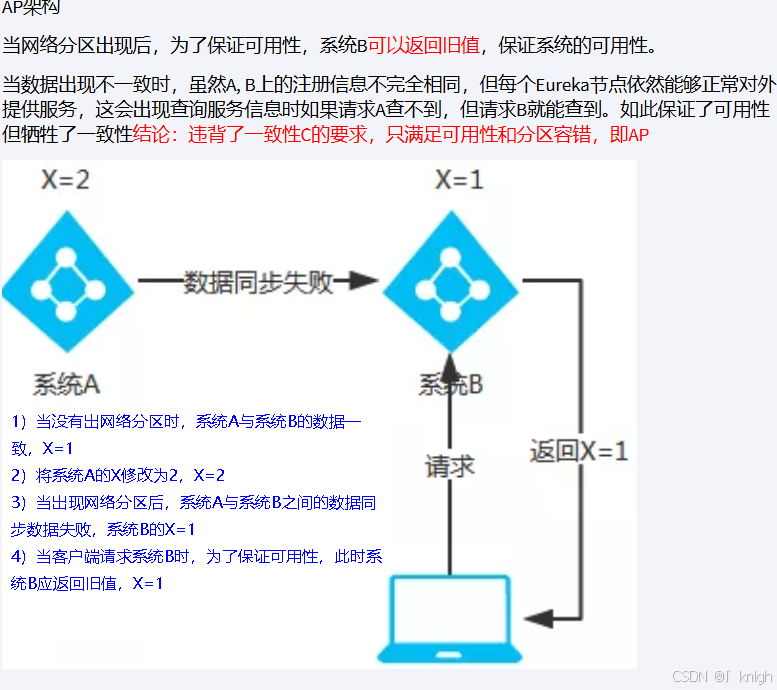
CP
服务配置
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。比如某些配置文件中的内容大部分都是相同的,只有个别的配置项不同。就拿数据库配置来说吧,如果每个微服务使用的技术栈都是相同的,则每个微服务中关于数据库的配置几乎都是相同的,有时候主机迁移了,我希望一次修改,处处生效。
当下我们每一个微服务自己带着一个application.yml,上百个配置文件的管理....../(ㄒoㄒ)/~~
官网说明

步骤服务提供者8001
修改pom
<!--SpringCloud consul config--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-config</artifactId> </dependency> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency>
新建bootstrap.yml
把application.yml中一些东西提到bootstrap.yml
spring:application:name: cloud-payment-service####Spring Cloud Consul for Service Discoverycloud:consul:host: localhostport: 8500discovery:service-name: ${spring.application.name}config:profile-separator: '-' # default value is ",",we update '-'format: YAML# config/cloud-payment-service/data
# /cloud-payment-service-dev/data
# /cloud-payment-service-prod/data
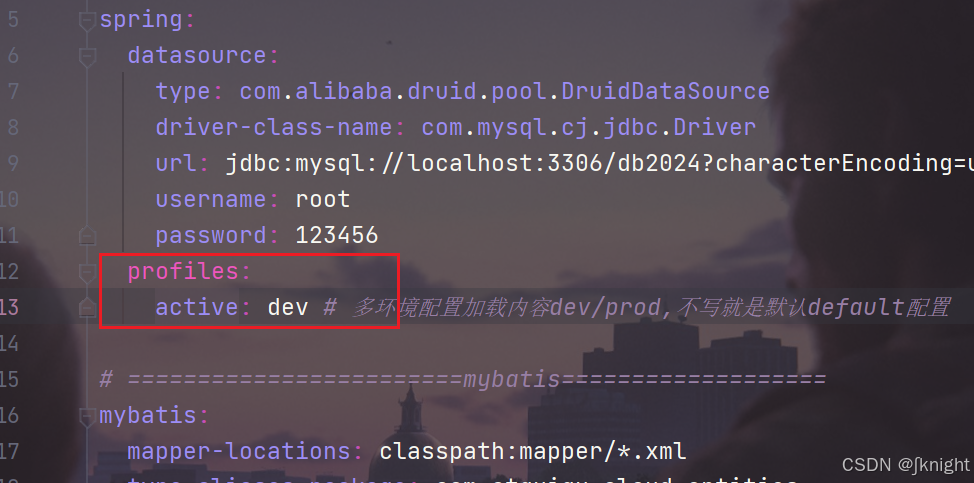
application.yml
server:port: 8001# ==========applicationName + druid-mysql8 driver=================== spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/db2024?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=trueusername: rootpassword: 123456profiles:active: dev # 多环境配置加载内容dev/prod,不写就是默认default配置# ========================mybatis=================== mybatis:mapper-locations: classpath:mapper/*.xmltype-aliases-package: com.atguigu.cloud.entitiesconfiguration:map-underscore-to-camel-case: true
8500新建config文件夹
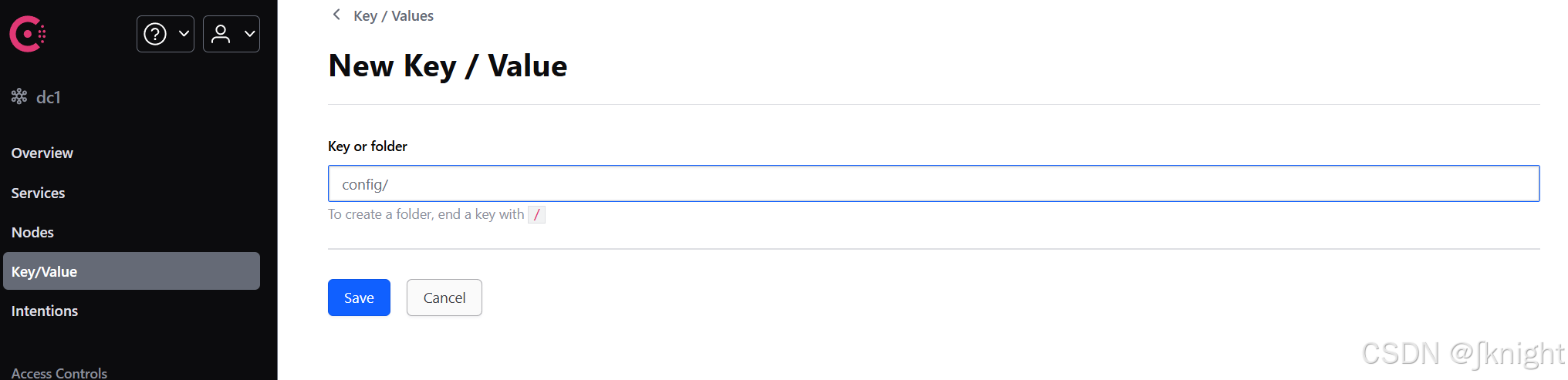
config下新建3个文件夹
这3个文件夹分别create data
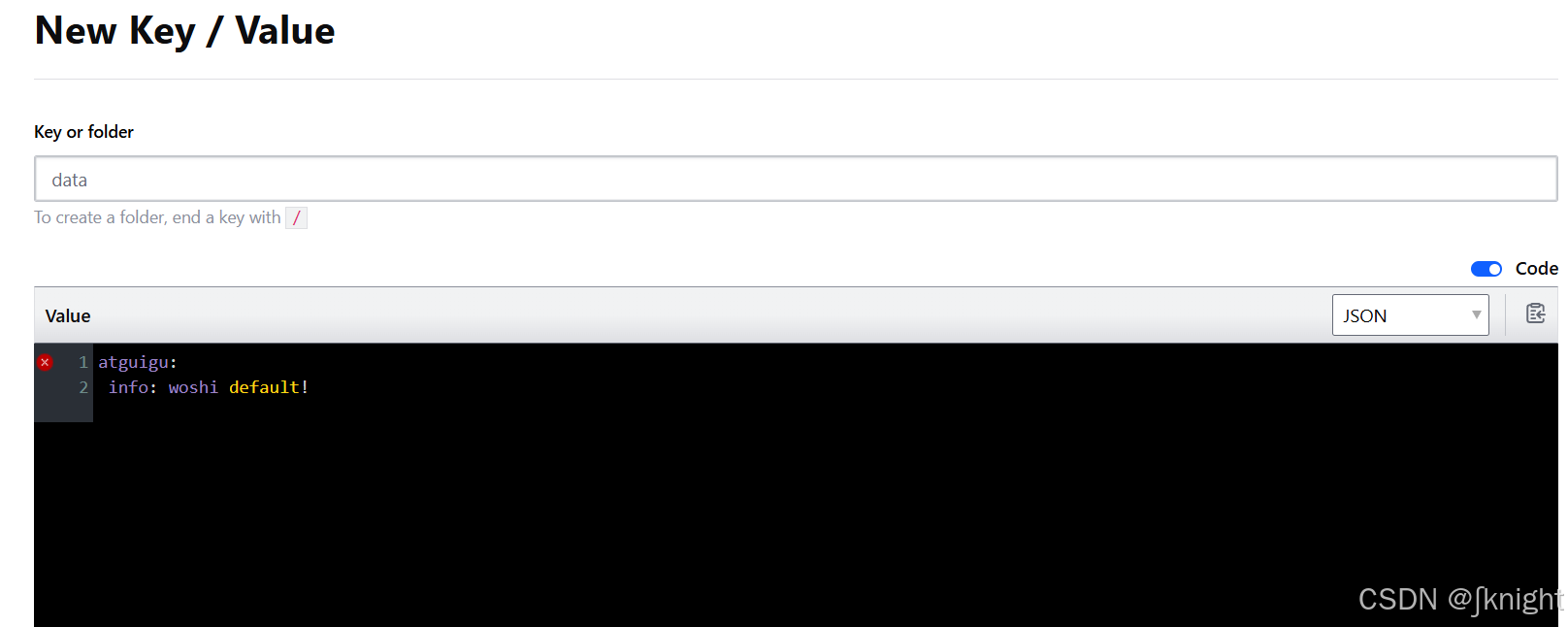
8001的controller中增加代码
@Value("${server.port}")
private String port;
@GetMapping(value = "/pay/get/info")
public String getInfoByConsul(@Value("${atguigu.info}") String atguigu){return "atguigu:"+atguigu+"\t"+"port"+port;
}
打开http://localhost:8001/pay/get/info
可以访问到

在idea中可以切换,会访问到consul中不同的内容
动态刷新
我们修改了consul的data内容,可能不会即时刷新,这时候需要进行配置

方法一:
主启动类添加注解
@RefreshScope
这个方法可能不生效,放在controller上也不行,不知道为什么,
方法二:官网有默认的时间是55秒,自己也可以修改
bootstrap.yml中增加
watch:
wait-time: 1
consul如果关闭,所有配置都会失效,需要重新配置
二、Spring Cloud LoadBalancer
在springcloudCommons这个包下面
LB负载均衡(Load Balance)是什么
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用),常见的负载均衡有软件Nginx,LVS,硬件F5等
spring-cloud-starter-loadbalancer组件是什么
Spring Cloud LoadBalancer是由SpringCloud官方提供的一个]源的、简单易用的客户端负载均衡器,,它包含在SpringCloud-commons中用它来换了以前的Ribbon组件。相比较于Ribbon,SpringCloud LoacBalancer不仅能够支持RestTemplate,还支持WebClient(WeClient是SpringWeb Flux中提供的功能,可以实现响应式异步请求)
loadbalancer本地负载均衡客户端 VS Nginx服务端负载均衡区别
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现的。
loadbalancer本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
80通过轮询负载访问8001/8002/8003
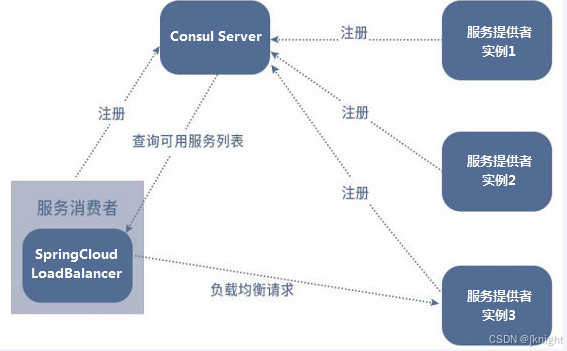
LoadBalancer 在工作时分成两步:
第一步,先选择ConsulServer从服务端查询并拉取服务列表,知道了它有多个服务(上图3个服务),这3个实现是完全一样的,
默认轮询调用谁都可以正常执行。类似生活中求医挂号,某个科室今日出诊的全部医生,客户端你自己选一个。
第二步,按照指定的负载均衡策略从server取到的服务注册列表中由客户端自己选择一个地址,所以LoadBalancer是一个客户端的负载均衡器。
idea中新建8002,把8001的复制过去,会发现访问localhost:8001/pay/get/info报错,这是因为consul在关闭后,之前设置的资源会消失,需要进行持久化
按上面图片的步骤在consul的安装目录新建。。。。。。。。
然后再8500中create config/。。。。。
就可以运行了 访问8001和8002都可以成功

订单80修改
1. POM
| <!--loadbalancer--> < dependency > < groupId >org.springframework.cloud </ groupId > < artifactId >spring-cloud-starter-loadbalancer </ artifactId > </ dependency |
此时访问80就会轮询访问8001和8002


原因
订单80的controller加入以下代码
@Resource
private DiscoveryClient discoveryClient;
@GetMapping("/consumer/discovery")
public String discovery()
{List<String> services = discoveryClient.getServices();for (String element : services) {System.out.println(element);}System.out.println("===================================");List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service");for (ServiceInstance element : instances) {System.out.println(element.getServiceId()+"\t"+element.getHost()+"\t"+element.getPort()+"\t"+element.getUri());}//这里的get是写死的,只能获取第一个return instances.get(0).getServiceId()+":"+instances.get(0).getPort();
}
浏览器访问,idea会打印,所有注册的服务和需要的服务
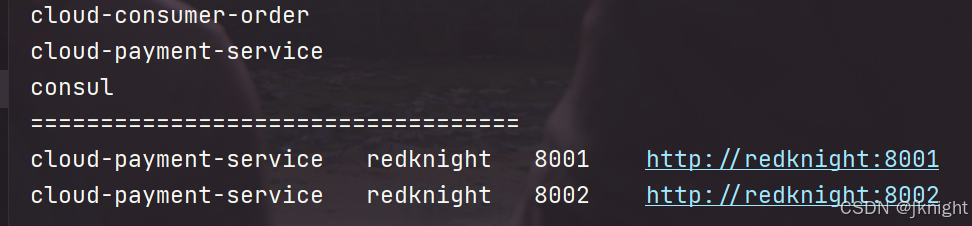
算法解释
| 负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始。 List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service"); 如: List [0] instances = 127.0.0.1:8002 List [1] instances = 127.0.0.1:8001 8001+ 8002 组合成为集群,它们共计2台机器,集群总数为2, 按照轮询算法原理: 当总请求数为1时: 1 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001 当总请求数位2时: 2 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002 当总请求数位3时: 3 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001 当总请求数位4时: 4 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002 如此类推...... |


切换负载均衡算法,
@LoadBalancerClient(value = "cloud-payment-service", configuration = RestTemplateConfig.class):该注解的作用是为名为cloud-payment-service的服务客户端定制负载均衡配置。configuration属性指定了配置类,也就是当前的RestTemplateConfig类 |
|
|
@Configuration // 服务名称 @LoadBalancerClient(value = "cloud-payment-service",configuration = RestTemplateConfig.class) public class RestTemplateConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate(){return new RestTemplate();}@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME); //RandomLoadBalancer 随机,不是轮询return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),name);} }
三、OpenFeign服务接口调用

官网:Spring Cloud OpenFeign
OpenFeign能干什么
前面在使用SpringCloud LoadBalancer+RestTempl,利用RestTemplate对http请求的封装处理形成了一套模版化的调用方法但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,OpenFeign在此基础上做]进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在OpenFeign的实现下,我们只需创建一个接口并使用解的方式来配置它(在一个微服务接口上面标注一个@Feignclient注解即可),即可完成对服务提供方的接口绑定,统一对外暴露可以被调用的接口方法,大大简化和降低了调用客户端的开发量,也即由服务提用即可,O(n n)O.
OpenFeign同时还集成SpringCloud LoadBalancer
可以在使用OpenFeign时提供Http客户端的负载均衡,也可以集成阿里巴巴Sentinel来提供熔断、降级等功能。而与SpringCloudLoadBalancer不同的是,通过OpenFeign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。

80调用服务提供者向外暴露的接口就可以,这个接口卸写在公共的里面,其他服务也可以直接调用
按照流程new moudle,改pom,重新搞一个80端口
cloud-consumer-feign-order80
额外引入依赖
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
yml
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
主启动类
添加@EnableFeignClients注解
@SpringBootApplication
@EnableDiscoveryClient // 向使用consul为注册中心时提供服务
@EnableFeignClients // 启用feign客户端,定义服务+绑定接口,以声明式的方法优雅而简单的实现服务调用
public class MainOpenFeign80 {public static void main(String[] args) {SpringApplication.run(MainOpenFeign80.class);}
}
书写controller代码
这里controller,注入了下面公共api-commons中接口,然后调用接口中的方法
@RestController
public class OrderController {@Resourceprivate PayFeignApi payFeignApi;@PostMapping("/feign/pay/add")public ResultData addOrder(@RequestBody PayDTO payDTO){ResultData resultData = payFeignApi.addPay(payDTO);return resultData;}@GetMapping("/feign/pay/get/{id}")public ResultData getPayInfo(@PathVariable("id") Integer id){ResultData payInfo = payFeignApi.getPayInfo(id);return payInfo;}@GetMapping("/feign/pay/mylb")public String mylb(){return payFeignApi.mylb();}
}
api-commons中引入依赖
<!--openfeign--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
新建接口 PayFeignApi
value指向的是消费提供者8001,8002的服务
@FeignClient(value = "cloud-payment-service")
public interface PayFeignApi {/*** 新增一条支付相关流水记录* @param payDTO* @return*/@PostMapping(value = "/pay/add")public ResultData addPay(@RequestBody PayDTO payDTO);/*** 按照主键记录查询支付流水信息* @param id* @return*/@GetMapping(value = "/pay/get/{id}")public ResultData getPayInfo(@PathVariable("id") Integer id);/*** openfeign天然支持负载均衡演示* @return*/@GetMapping(value = "/pay/get/info")public String mylb();
}
测试
默认支持负载均衡,在8001和8002之间轮询

高级特性
超时控制

在Spring Cloud微服务架构中,大部分公司都是利用OpenFeign进行服务间的调用,而比较简单的业务使用默认配置是不会有多大问题的,但是如果是业务比较复杂,服务要进行比较繁杂的业务计算,那后台很有可能会出现Read Timeout这个异常,因此定制化配置超时时间就有必要了。
故意写bug,测试feign的超时时间
8001的controller
@GetMapping(value = "/pay/get/{id}")
@Operation(summary = "按照ID查流水",description = "查询支付流水方法")
public ResultData<Pay> getById(@PathVariable("id") Integer id)
{if (id==-1) throw new RuntimeException("不能为负数");// 暂停62秒,故意写bug try {TimeUnit.SECONDS.sleep(62);} catch (InterruptedException e) {e.printStackTrace();}Pay pay= payService.getById(id);return ResultData.success(pay);
}
80的controller
@GetMapping("/feign/pay/get/{id}")
public ResultData getPayInfo(@PathVariable("id") Integer id){System.out.println("按照订单查流水开始");ResultData resultData=null; try {System.out.println("调用开始+++"+ DateUtil.now());resultData=payFeignApi.getPayInfo(id);} catch (Exception e) {e.printStackTrace();System.out.println("调用结束+++"+ DateUtil.now());ResultData.fail(ReturnCodeEnum.RC500.getCode(),e.getMessage());}return resultData;
}
测试会发现,大概60秒后会超时报错


默认OpenFeign客户端等待60秒钟,但是服务端处理超过规定时间会导致Feign客户端返回报错。
为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制,默认60秒太长或者业务时间太短都不好
yml文件中开启配置:
connectTimeout 连接超时时间
readTimeout 请求处理超时时间

全局配置
80端口
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#连接超时时间
connectTimeout: 3000
#读取超时时间
readTimeout: 3000
超时时间变成3秒

指定配置
指定的会覆盖全局的,指定的是服务名称这里是cloud-payment-service
server:port: 80spring:application:name: cloud-consumer-openfeign-order####Spring Cloud Consul for Service Discoverycloud:consul:host: localhostport: 8500discovery:prefer-ip-address: true #优先使用服务ip进行注册service-name: ${spring.application.name}openfeign:client:config:default:connectTimeout: 4000 #连接超时时间readTimeout: 4000 #读取超时时间 cloud-payment-service: #服务名称connectTimeout: 8000 #连接超时时间readTimeout: 8000 #读取超时时间
访问localhost/feign/pay/get/1 结果是8秒

OpenFeign重试机制

新增config
@Configuration
public class FeignConfig {@Beanpublic Retryer myRetryer(){
// return Retryer.NEVER_RETRY; //Feign默认不走重试策略
//最大请求次数为3(1+2),初始间隔时间为100ms,重试间最大间隔时间为1s return new Retryer.Default(100,1,3);}
}
Retryer接口源码

测试结果 是12秒 4+8
这里应当把8002停了,只开8001才可以成功
8002是正常的,会正常返回值,8001是自己设置的有错误

OpenFeign默认http client修改

OpenFeign中http client
如果不做特殊配置,OpenFeign默认使用JDK自带的HttpURLConnection发送HTTP请求,
由于默认HttpURLConnection没有连接池、性能和效率比较低,如果采用默认,性能上不是最牛B的,所以加到最大。
改pom
<!-- httpclient5-->
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.3</version>
</dependency>
<!-- feign-hc5-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-hc5</artifactId>
<version>13.1</version>
</dependency>
修改yml
server:port: 80spring:application:name: cloud-consumer-openfeign-order####Spring Cloud Consul for Service Discoverycloud:consul:host: localhostport: 8500discovery:prefer-ip-address: true #优先使用服务ip进行注册service-name: ${spring.application.name}openfeign:client:config:default:connectTimeout: 2000 #连接超时时间readTimeout: 2000 #读取超时时间cloud-payment-service:connectTimeout: 4000 #连接超时时间readTimeout: 4000 #读取超时时间 httpclient:hc5:enabled: true
替换前

替换后

OpenFeign请求和压缩

对请求和响应进行GZIP压缩
Spring Cloud OpenFeign支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。
通过下面的两个参数设置,就能开启请求与相应的压缩功能:
spring.cloud.openfeign.compression.request.enabled=true
spring.cloud.openfeign.compression.response.enabled=true
细粒度化设置
对请求压缩做一些更细致的设置,比如下面的配置内容指定压缩的请求数据类型并设置了请求压缩的大小下限,
只有超过这个大小的请求才会进行压缩:
spring.cloud.openfeign.compression.request.enabled=true
spring.cloud.openfeign.compression.request.mime-types=text/xml,application/xml,application/json #触发压缩数据类型
spring.cloud.openfeign.compression.request.min-request-size=2048 #最小触发压缩的大小
yml
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间
connectTimeout: 4000
#读取超时时间
readTimeout: 4000
httpclient:
hc5:
enabled: true
compression:
request:
enabled: true
min-request-size: 2048 #最小触发压缩的大小
mime-types: text/xml,application/xml,application/json #触发压缩数据类型
response:
enabled: true
OpenFeign日志打印功能
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,
从而了解 Feign 中 Http 请求的细节,
说白了就是对Feign接口的调用情况进行监控和输出
级别
NONE:默认的,不显示任何日志;

config
@Configuration
public class FeignConfig {@Beanpublic Retryer myRetryer(){return Retryer.NEVER_RETRY; //Feign默认不走重试策略//最大请求次数为3(1+2),初始间隔时间为100ms,重试间最大间隔时间为1s
// return new Retryer.Default(100,1,3);} @BeanLogger.Level feignLoggerLevel(){return Logger.Level.FULL;}
}
yml
server:port: 80spring:application:name: cloud-consumer-openfeign-order####Spring Cloud Consul for Service Discoverycloud:consul:host: localhostport: 8500discovery:prefer-ip-address: true #优先使用服务ip进行注册service-name: ${spring.application.name}openfeign:client:config:default:connectTimeout: 4000 #连接超时时间readTimeout: 4000 #读取超时时间httpclient:hc5:enabled: true#cloud-payment-service:#connectTimeout: 4000 #连接超时时间#readTimeout: 4000 #读取超时时间compression:request:enabled: truemin-request-size: 2048 #最小触发压缩的大小mime-types: text/xml,application/xml,application/json #触发压缩数据类型response:enabled: true
# feign日志以什么级别监控哪个接口
logging:level:com:atguigu:cloud:apis:PayFeignApi: debug
带着压缩调用

去掉压缩调用

修改config
这里把return修改
@Configuration
public class FeignConfig {@Beanpublic Retryer myRetryer(){
// return Retryer.NEVER_RETRY; //Feign默认不走重试策略//最大请求次数为3(1+2),初始间隔时间为100ms,重试间最大间隔时间为1s return new Retryer.Default(100,1,3);}@BeanLogger.Level feignLoggerLevel(){return Logger.Level.FULL;}
} 测试会看到3次请求。




如果把yml中的log去掉,就是一次普通的打印,不显示上面的请求

四、CircuitBreaker断路器
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
了解一下即可,2024年了不再使用Hystrix


分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。

服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,
通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
问题:
禁止服务雪崩故障
解决:
- 有问题的节点,快速熔断(快速返回失败处理或者返回默认兜底数据【服务降级】)。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
一句话,出故障了“保险丝”跳闸,别把整个家给烧了,😄

CircuitBreak是什么
CircuitBreaker的目的是保护分布式系统免受故障和异常,提高系统的可用性和健壮性。
当一个组件或服务出现故障时,CircuitBreaker会迅速切换到开放OPEN状态(保险丝跳闸断电),阻止请求发送到该组件或服务从而避免更多的请求发送到该组件或服务。这可以减少对该组件或服务的负载,防止该组件或服务进一步崩溃,并使整个系统能够继续正常运行。同时,CircuitBreaker还可以提高系统的可用性和健壮性,因为它可以在分布式系统的各个组件之间自动切换,从而避免单点故障的问题
CircuitBreak是一套规范和接口,落地实现是Resilience4J


什么是Resilience4j
Resilience4j 是一个轻量级的容错库,专为函数式编程而设计。 Resilience4j 提供高阶函数(装饰器)来增强任何功能接口, 具有 Circuit Breaker、Rate Limiter、Retry 或 Bulkhead 的 lambda 表达式或方法引用。 您可以在任何功能接口、lambda 表达式或方法引用上堆叠多个装饰器。 优点是您可以选择所需的装饰器,而不是其他任何选择。
Resilience4j 2 需要 Java 17
Resilience4j 提供了几个核心模块:
-
resilience4j-circuitbreaker: 熔断
-
resilience4j-ratelimiter:速率限制
-
resilience4j-bulkhead: 隔板
-
resilience4j-retry:自动重试(同步和异步)
-
resilience4j-timelimiter:超时处理
-
resilience4j-cache:结果缓存
还有用于度量、Feign、Kotlin、Spring、Ratpack、Vertx、RxJava2 等的附加模块
断路器(CircuitBreaker)
断路器有三个普通状态:关闭(CLOSED)、开启(OPEN)、半开(HALF OPEN),
还有两个特殊状态:禁用
(DISABLED)、强制开启(FORCED OPEN)。
当熔断器关闭时,所有的请求都会通过熔断器,
。如果失败率超过设定的阈值,熔断器就会从关闭状态转换到打开状态,这时所有的请求都会被拒绝
当经过一段时间后,熔断器会从打开状态转换到半开状态,这时仅有一定数量的请求会被放入,并重新计算失败率
。如果失败率超过阈值,则变为打开状态,如果失败率低于阈值,则变为关闭状态。断路器使用滑动窗口来存储和统计调用的结果。你可以选择基于调用数量的滑动窗口或基于时间的滑动窗口。
基于访问数量的滑动窗口统计最近N次调用的返回结果。居于时间的滑动窗口统计最近N秒的调用0回结果。
除此以外,熔断器还会有两种特殊状态:DISABLED(始终允许访问)和FORCED OPEN(始终拒绝访问)这两个状态不会生成熔断器事件(除状态装换外),并且不会记录事件的成功或者失败。
退出这两个状态的唯一方法是触发状态转换或者重置熔断器。
精简概念
| failure-rate-threshold | 以百分比配置失败率峰值 |
| sliding-window-type | 断路器的滑动窗口期类型 |
| sliding-window-size | 若COUNT_BASED,则10次调用中有50%失败(即5次)打开熔断断路器; 若为TIME_BASED则,此时还有额外的两个设置属性,含义为:在N秒内(sliding-window-size)100%(slow-call-rate-threshold)的请求超过N秒(slow-call-duration-threshold)打开断路器。 |
| slowCallRateThreshold | 以百分比的方式配置,断路器把调用时间大于slowCallDurationThreshold的调用视为慢调用,当慢调用比例大于等于峰值时,断路器开启,并进入服务降级。 |
| slowCallDurationThreshold | 配置调用时间的峰值,高于该峰值的视为慢调用。 |
| permitted-number-of-calls-in-half-open-state | 运行断路器在HALF_OPEN状态下时进行N次调用,如果故障或慢速调用仍然高于阈值,断路器再次进入打开状态。 |
| minimum-number-of-calls | 在每个滑动窗口期样本数,配置断路器计算错误率或者慢调用率的最小调用数。比如设置为5意味着,在计算故障率之前,必须至少调用5次。如果只记录了4次,即使4次都失败了,断路器也不会进入到打开状态。 |
| wait-duration-in-open-state | 从OPEN到HALF_OPEN状态需要等待的时间 |
# 6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。
# 等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。
# 如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。具体时间和频次等属性见具体实际案例,这里只是作为case举例讲解,最下面笔记面试题概览,闲聊大厂面试

面试真题


COUNT_BASED计数的滑动窗口
cloud-consumer-feign-order80 改pom
<!--resilience4j-circuitbreaker-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- 由于断路保护等需要AOP实现,所以必须导入AOP包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
yml新增
# 开启circuitbreaker和分组激活 spring.cloud.openfeign.circuitbreaker.enabled
circuitbreaker:
enabled: true
group:
enabled: true #没开分组永远不用分组的配置。精确优先、分组次之(开了分组)、默认最后# Resilience4j CircuitBreaker 按照次数:COUNT_BASED 的例子
# 6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。
# 等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。
# 如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。
resilience4j:
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slidingWindowType: COUNT_BASED # 滑动窗口的类型
slidingWindowSize: 6 #滑动窗⼝的⼤⼩配置COUNT_BASED表示6个请求,配置TIME_BASED表示6秒
minimumNumberOfCalls: 6 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。如果minimumNumberOfCalls为10,则必须最少记录10个样本,然后才能计算失败率。如果只记录了9次调用,即使所有9次调用都失败,断路器也不会开启。
automaticTransitionFromOpenToHalfOpenEnabled: true # 是否启用自动从开启状态过渡到半开状态,默认值为true。如果启用,CircuitBreaker将自动从开启状态过渡到半开状态,并允许一些请求通过以测试服务是否恢复正常
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。在半开状态下,CircuitBreaker将允许最多permittedNumberOfCallsInHalfOpenState个请求通过,如果其中有任何一个请求失败,CircuitBreaker将重新进入开启状态。
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default
new controller
@RestController
public class OrderCircuitController
{@Resourceprivate PayFeignApi payFeignApi;@GetMapping(value = "/feign/pay/circuit/{id}")
@CircuitBreaker(name = "cloud-payment-service", fallbackMethod = "myCircuitFallback")// fallbackMethod 调用失败会调用的方法public String myCircuitBreaker(@PathVariable("id") Integer id){return payFeignApi.myCircuit(id);}//myCircuitFallback就是服务降级后的兜底处理方法public String myCircuitFallback(Integer id,Throwable t) {// 这里是容错处理逻辑,返回备用结果return "myCircuitFallback,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";}
} 正常访问的页面

不正常访问时

这里如果正常访问3次,不正常访问3次,就会熔断,此时正常访问的页面也会变为不正常的
再等5秒,又可以正常访问了,
50%错误后触发熔断并给出服务降级,告知调用者服务不可用
此时就算是输入正确的访间地址也无法调用服务(我明明是正确的也不让用/ToT人~),它还在断路中(PEN状态),一会儿过度到半开并继续正确地址访问,慢慢切换回CLOSE状态,可以正常访问了链路回复

TIME_BASED 时间的滑动窗口

yml
# Resilience4j CircuitBreaker 按照时间:TIME_BASED 的例子
resilience4j:
timelimiter:
configs:
default:
timeout-duration: 10s #神坑的位置,timelimiter 默认限制远程1s,超于1s就超时异常,配置了降级,就走降级逻辑
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slowCallDurationThreshold: 2s #慢调用时间阈值,高于这个阈值的视为慢调用并增加慢调用比例。
slowCallRateThreshold: 30 #慢调用百分比峰值,断路器把调用时间⼤于slowCallDurationThreshold,视为慢调用,当慢调用比例高于阈值,断路器打开,并开启服务降级
slidingWindowType: TIME_BASED # 滑动窗口的类型
slidingWindowSize: 2 #滑动窗口的大小配置,配置TIME_BASED表示2秒
minimumNumberOfCalls: 2 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default
本来可以正常访问

访问几次9999之后就会报错,等会就又可以访问了


隔离BulkHead是什么?
resilience4j 的 Bulkhead 模块实现并发控制,用于限制方法调用的并发数。
Bulkhead隔离不同种类的调用,并进行流控,这样可以避免某类调用异常或占用过多资源,危及系统整体。
实现方式用两种:
通过信号量Semaphores控制
通过线程池控制,使用一个有界队列和一个固定数量线程池。
信号量与线程池比较
信号量模式
信号量Semaphore是一个并发工具类,用来控制可同时并发的线程数,其内部维护了一组虚拟许可,通过构造器指定许可的数量,每次线程执行操作时先通过acquire方法获得许可,执行完毕再通过release方法释放许可。如果无可用许可,那么acquire方法将一直阻塞,直到其它线程释放许可。在该模式下,接收请求和执行下游依赖在同一个线程内完成,不存在线程上下文切换所带来的性能开销,所以大部分场景应该选择信号量模式。
由于该模式不创建线程,不适合并行任务的情况。
线程池模式
线程池用来控制实际工作的线程数量,通过线程复用的方式来减小内存开销。线程池可同时工作的线程数量是一定的,超过该数量的线程需进入线程队列等待,直到有可用的工作线程来执行任务。
作用是限制并发。依赖隔离&负载保护:用于限制对于下游服务的最大并发数量的限制
Resilience4j提供两种隔离机制:
-
信号量舱壁SemaphhoreBulkhead
-
固定线程池舱壁FixedThreadPoolBulkhead
bulkhead(船的)舱壁/(飞机的)隔板
隔板来自造船行业,床仓内部一般会分成很多小隔舱,一旦一个隔舱漏水因为隔板的存在而不至于影响其它隔舱和整体船。

信号量舱壁SemaphoreBulkhead
基本上就是我们JUC信号灯内容的同样思想

信号量舱壁(SemaphoreBulkhead)原理
当信号量有空闲时,进入系统的请求会直接获取信号量并开始业务处理。
当信号量全被占用时,接下来的请求将会进入阻塞状态,SemaphoreBulkhead提供了一个阻塞计时器,
如果阻塞状态的请求在阻塞计时内无法获取到信号量则系统会拒绝这些请求。
若请求在阻塞计时内获取到了信号量,那将直接获取信号量并执行相应的业务处理
按照下面流程进行

直接从80开始了,改pom
<!--resilience4j-bulkhead-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
</dependency>
yml
####resilience4j bulkhead 的例子 resilience4j:bulkhead:configs:default:maxConcurrentCalls: 2 # 隔离允许并发线程执行的最大数量maxWaitDuration: 1s # 当达到并发调用数量时,新的线程的阻塞时间,我只愿意等待1秒,过时不候进舱壁兜底fallbackinstances:cloud-payment-service:baseConfig: defaulttimelimiter:configs:default:timeout-duration: 20s
controller
/**
*(船的)舱壁,隔离
* @param id
* @return
*/
@GetMapping(value = "/feign/pay/bulkhead/{id}")
@Bulkhead(name = "cloud-payment-service",fallbackMethod = "myBulkheadFallback",type = Bulkhead.Type.SEMAPHORE)
public String myBulkhead(@PathVariable("id") Integer id)
{
return payFeignApi.myBulkhead(id);
}
public String myBulkheadFallback(Throwable t)
{
return "myBulkheadFallback,隔板超出最大数量限制,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";
}
这里结果没运行出来,还没找到是哪里的错误,可能是因为
请求并非严格并发,导致信号量未被占满。
这里在postman中可以产生预期结果,浏览器中不能

结果

固定线程池
基本上就是我们JUC-线程池内容的同样思想

固定线程池舱壁(FixedThreadPoolBulkhead)
FixedThreadPoolBulkhead的功能与SemaphoreBulkhead一样也是用于限制并发执行的次数的,但是二者的实现原理存在差别而且表现效果也存在细微的差别。FixedThreadPoolBulkhead使用一个固定线程池和一个等待队列来实现舱壁。
当线程池中存在空闲时,则此时进入系统的请求将直接进入线程池开启新线程或使用空闲线程来处理请求。
当线程池中无空闲时时,接下来的请求将进入等待队列,
若等待队列仍然无剩余空间时接下来的请求将直接被拒绝,
在队列中的请求等待线程池出现空闲时,将进入线程池进行业务处理。
另外:ThreadPoolBulkhead只对CompletableFuture方法有效,所以我们必创建返回CompletableFuture类型的方法