导航网站搭建济南seo优化
前言:
SHAP(SHapley Additive explanations) 是一种基于博弈论的可解释工具。 现在很多高分的
论文里面都会带这种基于SHAP 分析的图,用于评估机器学习模型中特征对预测结果的贡献度.
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple shap
目录:
- 边际贡献(Marginal Contribution of member)
- SHAP值计算(基于Shapley值)
- 机器学习SHAP应用
- 机器学习中SHAP 如何计算
- SHAP 分类
- Python 例子待补充
一 边际贡献(Marginal Contribution of member)
已知某公司通过三种广告源:A(抖音)、B(微信)、C(广告传单))不同广告组合的收益如下:
| 投放情况(x) | 收益f(x) |
| A | f(A) = 10(仅A投放时的收益) |
| B | f(B) = 30(仅B投放时的收益) |
| C | f(C) = 5(仅C投放时的收益) |
| A+B | f(A+B) = 50(A和B一起投放时的收益) |
| A+C | f(A+C) = 40(A和C一起投放时的收益) |
| B+C | f(B+C) = 35(B和C一起投放时的收益) |
| A+B+C | f(A+B+C) = 100(所有三个一起投放时的总收益) |
假设空集的收益 f(∅) = 0(即没有任何广告时收益为0),这是合作博弈论中的标准假设.
1.1 边际贡献:
指在合作博弈中,当一个成员(如i)加入一个现有联盟(如S)时,所带来的额外收益增加。
假设:
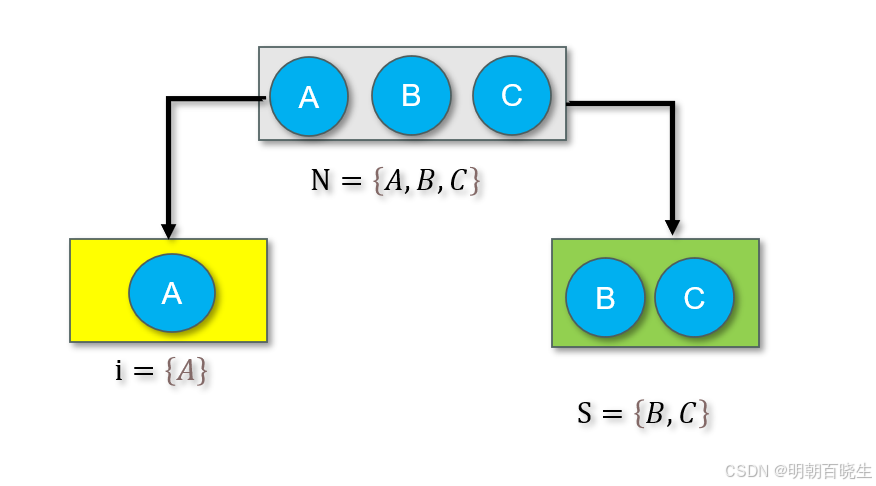
i: 成员
s: 子集,但是不包含成员i
N: 是所有成员的集合 本例子为:N={A,B,C}
则边际贡献为
f(s∪{i}) − f(s)
-
1.2 意义:
-
边际贡献衡量了成员在特定情境下的增量价值。然而,它依赖于成员加入的顺序和现有联盟的构成。因此,单一情境下的边际贡献可能无法公平反映成员的整体贡献(尤其当存在协同效应时)
-
1.3 我们计算每个广告源在加入“其他两个成员已组成的联盟”时的边际贡献
-
边际贡献
计算方法
解释
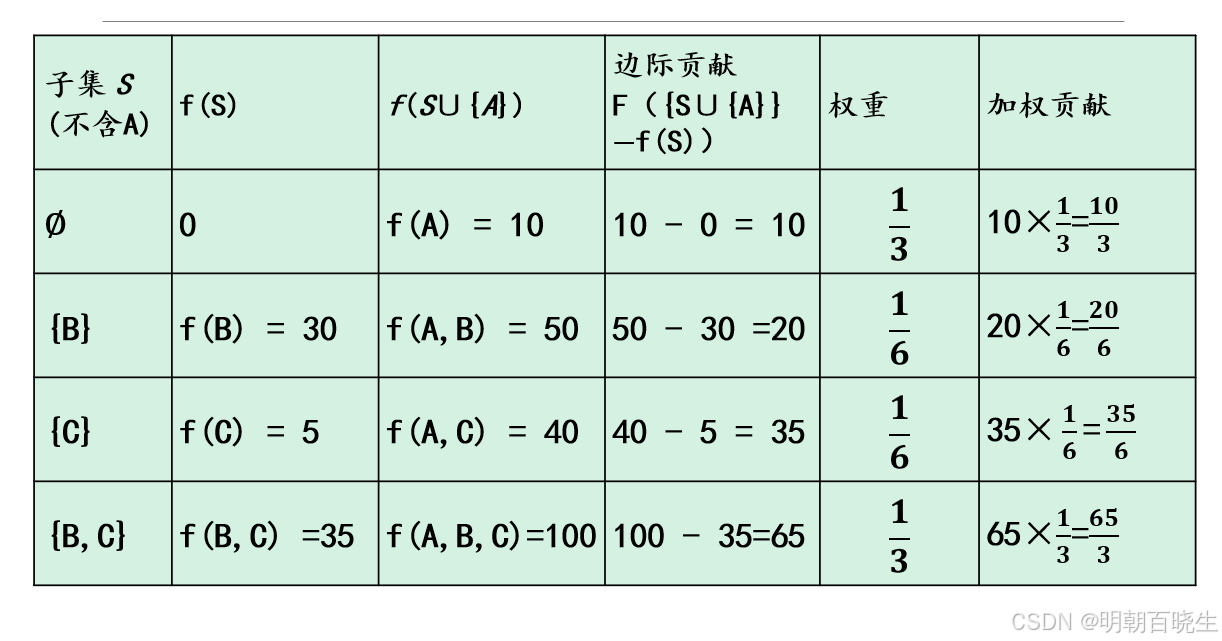
f({A,B,C})−f({B,C})=100−35=65
当B和C已经投放时,加入A带来65的额外收益
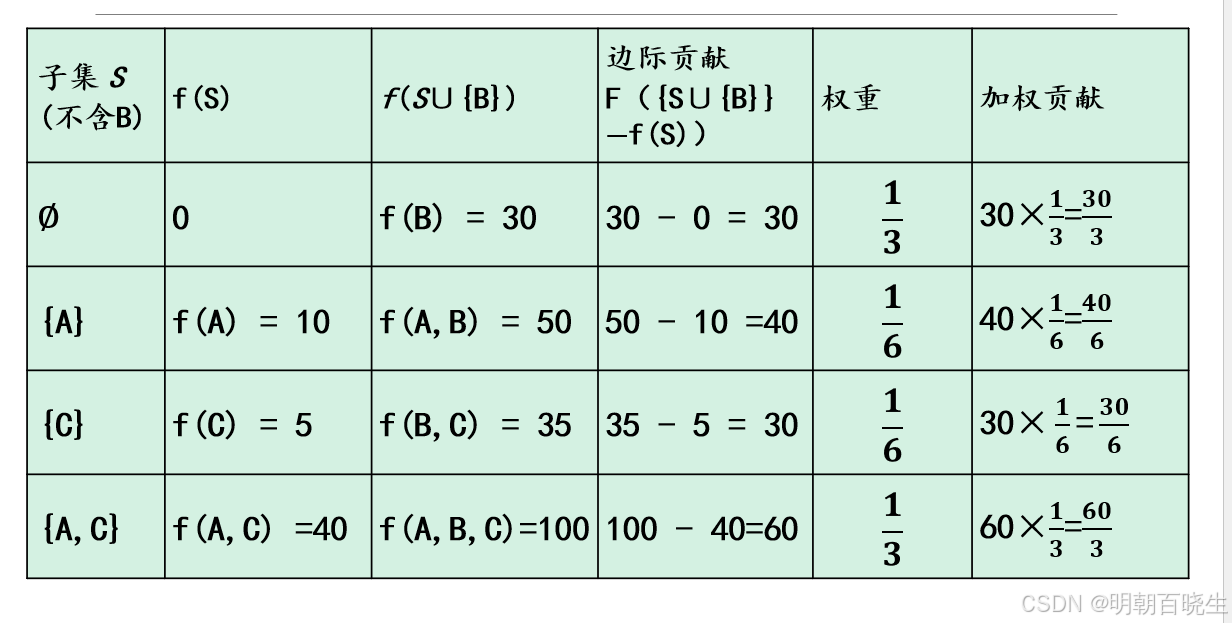
f({A,B,C})−f({A,C})=100−40=60
当A和C已经投放时,加入B带来60的额外收益。
f({A,B,C})−f({A,B})=100−50=50
当A和B已经投放时,加入C带来50的额外收益
1.4 边际贡献问题
结果:
这些值之和为 65+60+50=17565+60+50=175,但总收益仅为100。
这表明 广告源之间存在正向协同效应(例如,A和B一起的收益50 > 单独收益之和10+30=40)。简单边际贡献依赖于加入顺序,且未考虑所有可能情境,因此不适合直接分配总收益.
解决方案:
为了公平分配,需要使用平均边际贡献(即SHAP值/Shapley值),它考虑了所有可能的加入顺序。
二 SHAP值计算(基于Shapley值)
SHAP值(SHapley Additive exPlanations):起源于合作博弈论中的Shapley值,用于公平分配总收益(或解释模型预测)。它计算每个成员在所有可能加入顺序下的平均边际贡献,确保分配公平(即满足效率性:SHAP值之和等于总收益).

基于广告协同例子的计算

A(抖音)的SHAP值
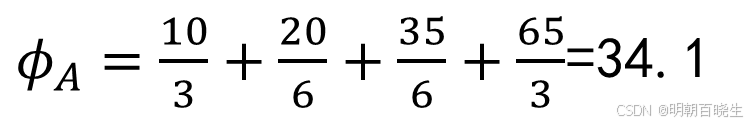
B(微信)的SHAP值
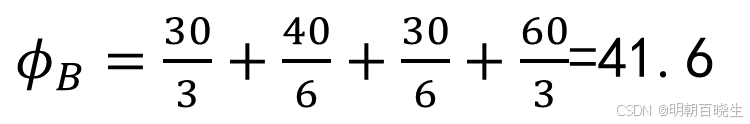
C(广告传单)的SHAP值:

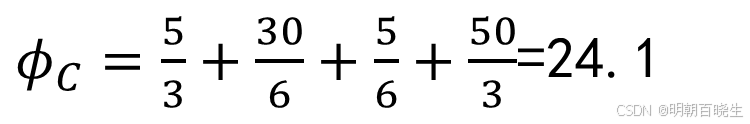
SHAP值(公平贡献度):
A(抖音):ϕA≈34.1667
B(微信):ϕB≈41.6667(或 25066250)
C(广告传单):ϕC≈24.1667
验证总和:ϕA+ϕB+ϕC==100,与总收益一致。
解释:
B(微信)的贡献最大(41.67),因为它单独和组合收益较高(f(B)=30, f(A+B)=50)。
A(抖音)次之(34.17),与B协同效应强 f(A+B)=50 > f(A)+f(B)=40
C(广告传单)贡献最小(24.17),单独收益低,但协同后仍有价值(例如,f(A,B,C)=100 > f(A,B)=50)
边际贡献 vs SHAP值:
边际贡献是情境依赖的单一值,而SHAP值是平均化的公平分配。
此例子中简单边际贡献(A:65, B:60, C:50)高估了贡献,而SHAP值(A:34.17, B:41.67, C:24.17)更合理地分配了总收益100。
应用场景:
在广告分析中,SHAP值可帮助优化预算分配(例如,减少C的投入,增加B的投入)。在机器学习中,SHAP值用于解释特征重要性
三 SHAP 机器学习应用
3.1 机器学习做SHAP 分析的原理
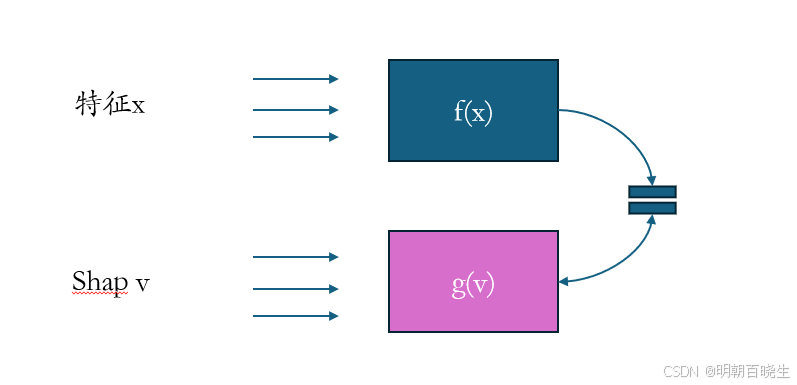
以线性回归为例,Additive Explanation Models,输入特征X ,输出f(x),我们
通过shape值 v ,以及shape计算方式 g(v) 可以得到 g(v)=f(x)
- 针对不同模型类型采用不同计算方法:
- 树模型:TreeSHAP算法(时间复杂度O(TLD^2))
- 线性模型:基于权重系数直接计算
- 深度模型:DeepSHAP方法
- 通用模型:KernelSHAP(基于LIME框架
3.2 SHAP 在Python 的用法
1: SHAP 初始化
2 单样本 SHAP 分析
多样本SHAP分析
多样本 SHAP bar 分析
多样本shap Beeswarm 分析

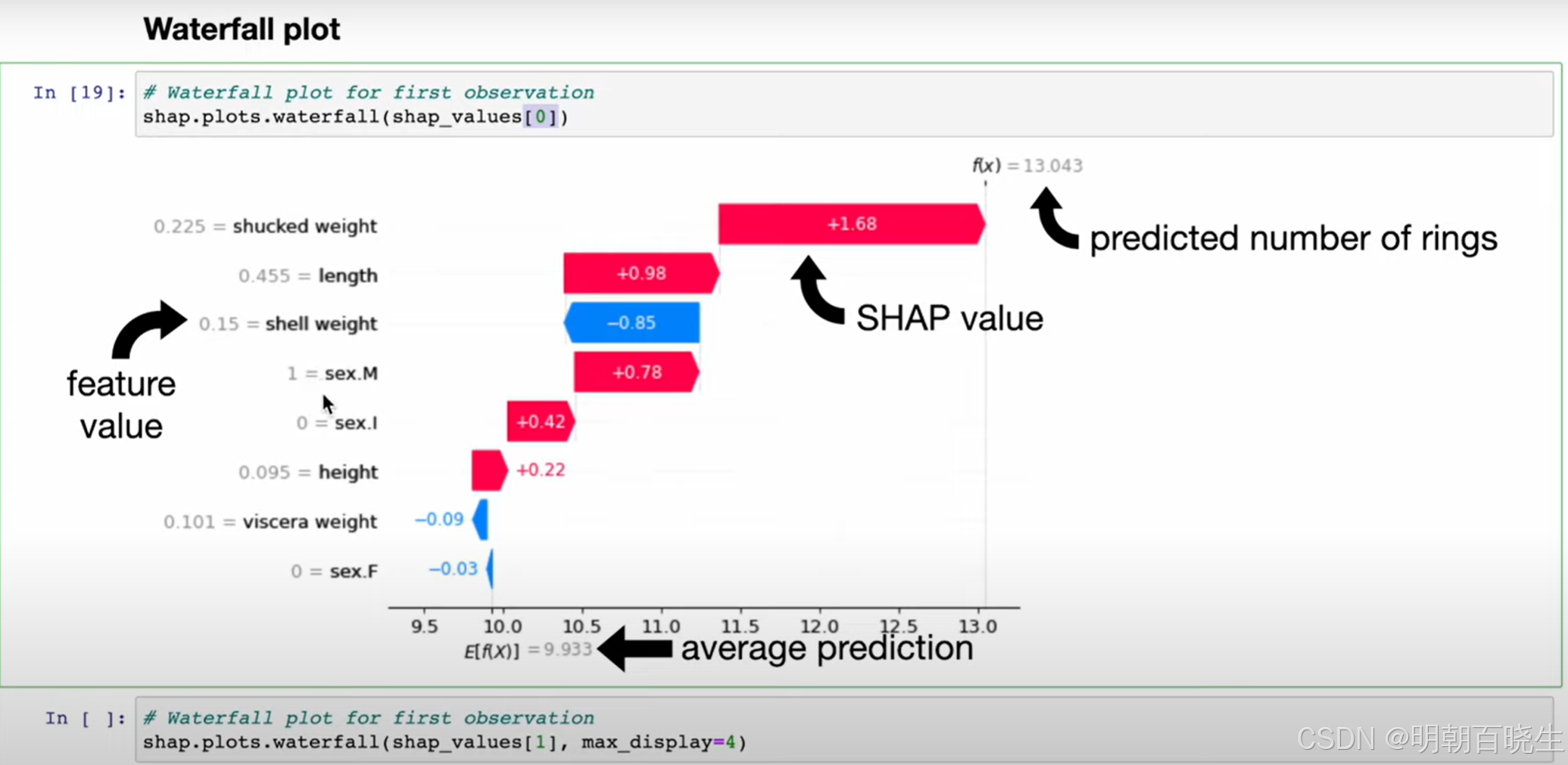
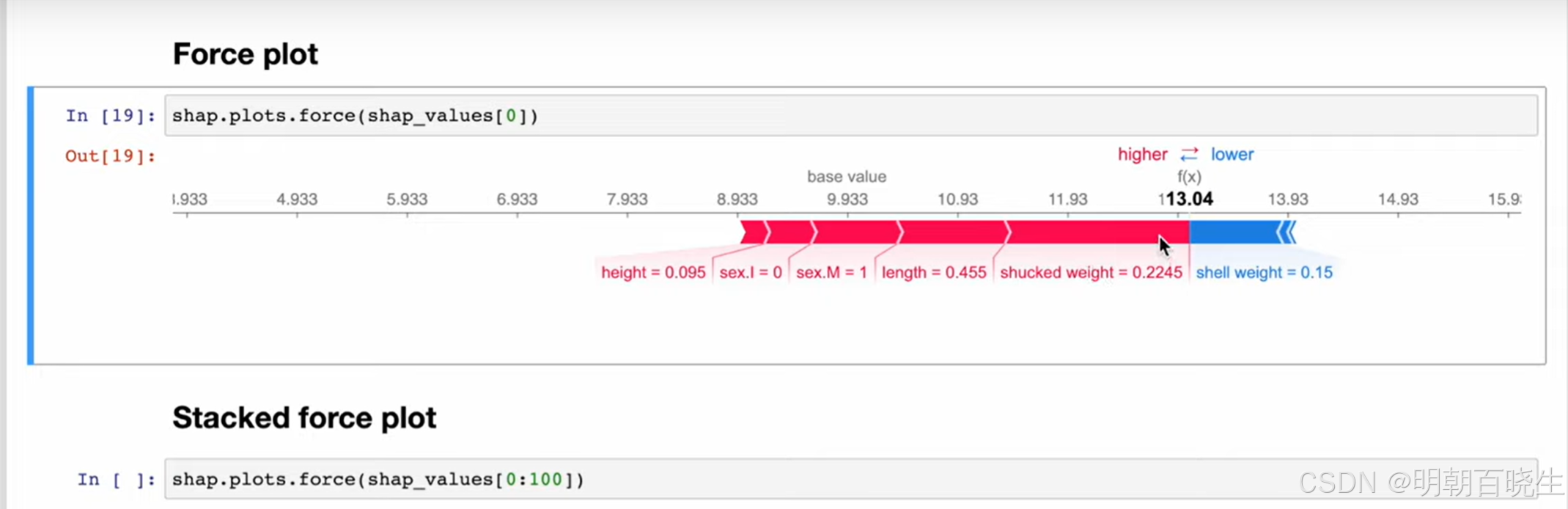
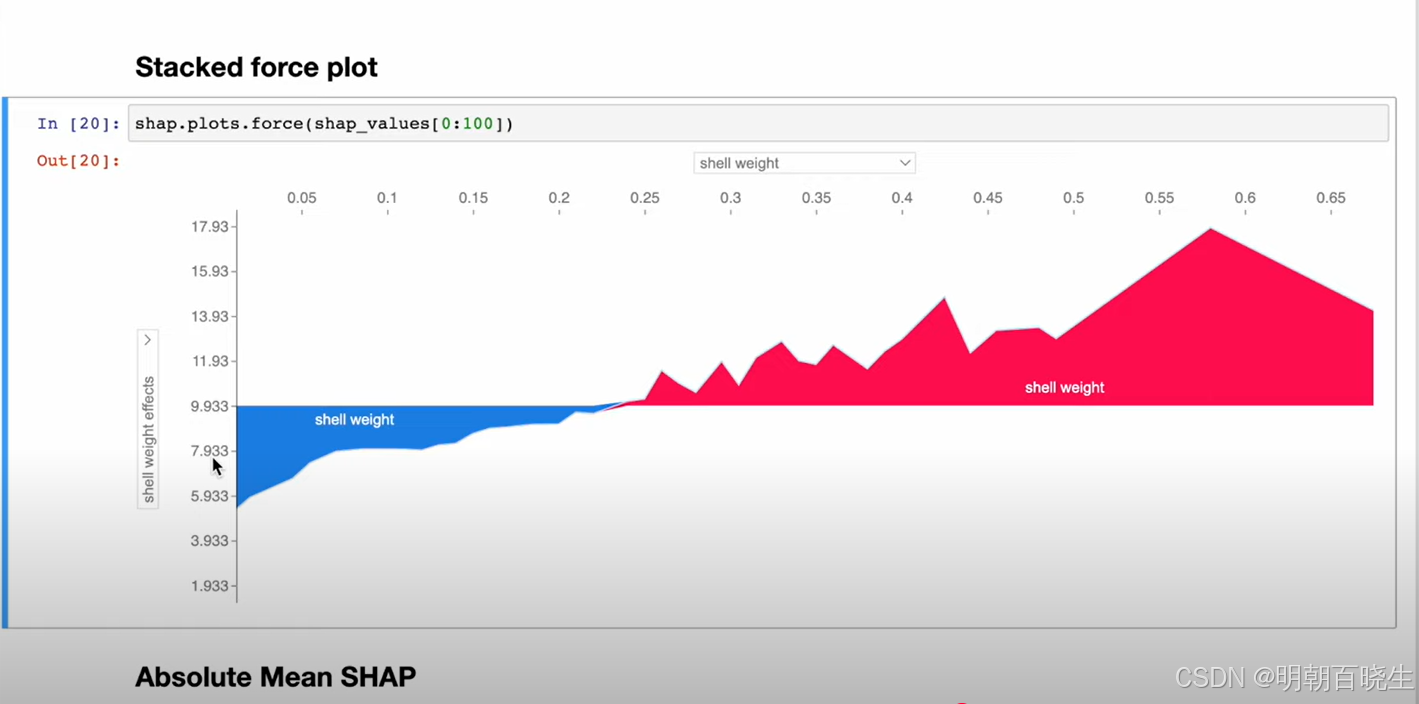
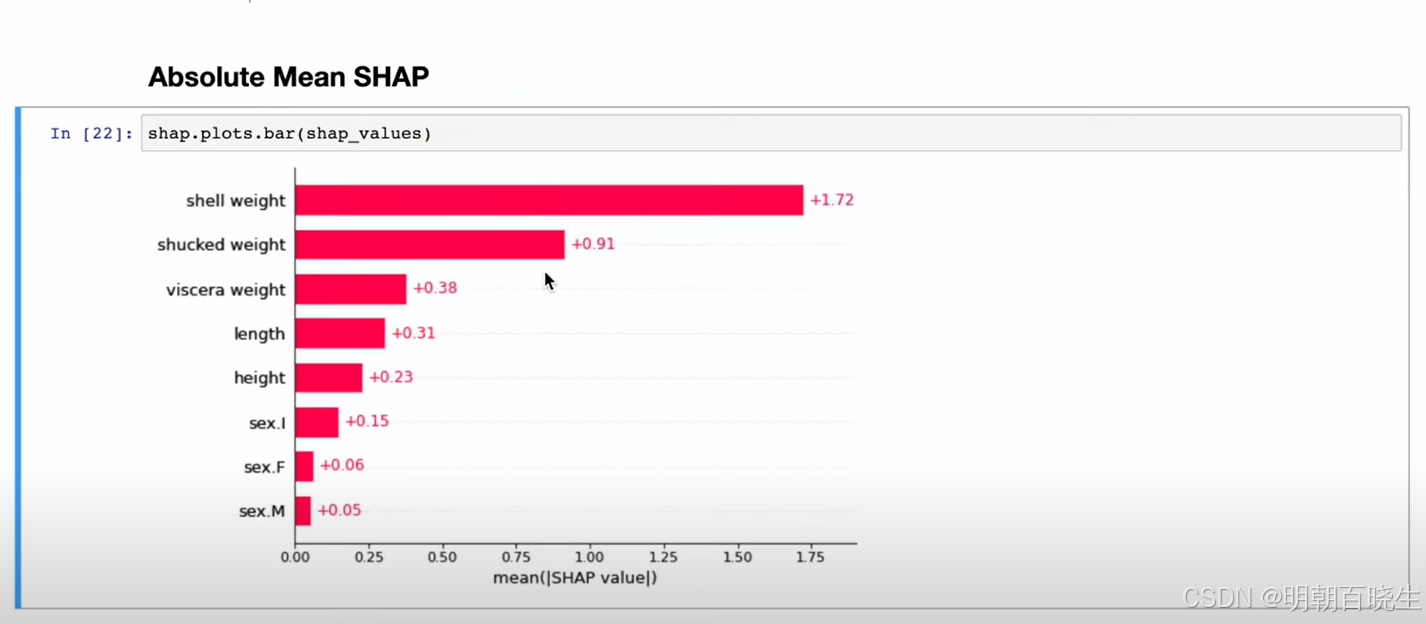
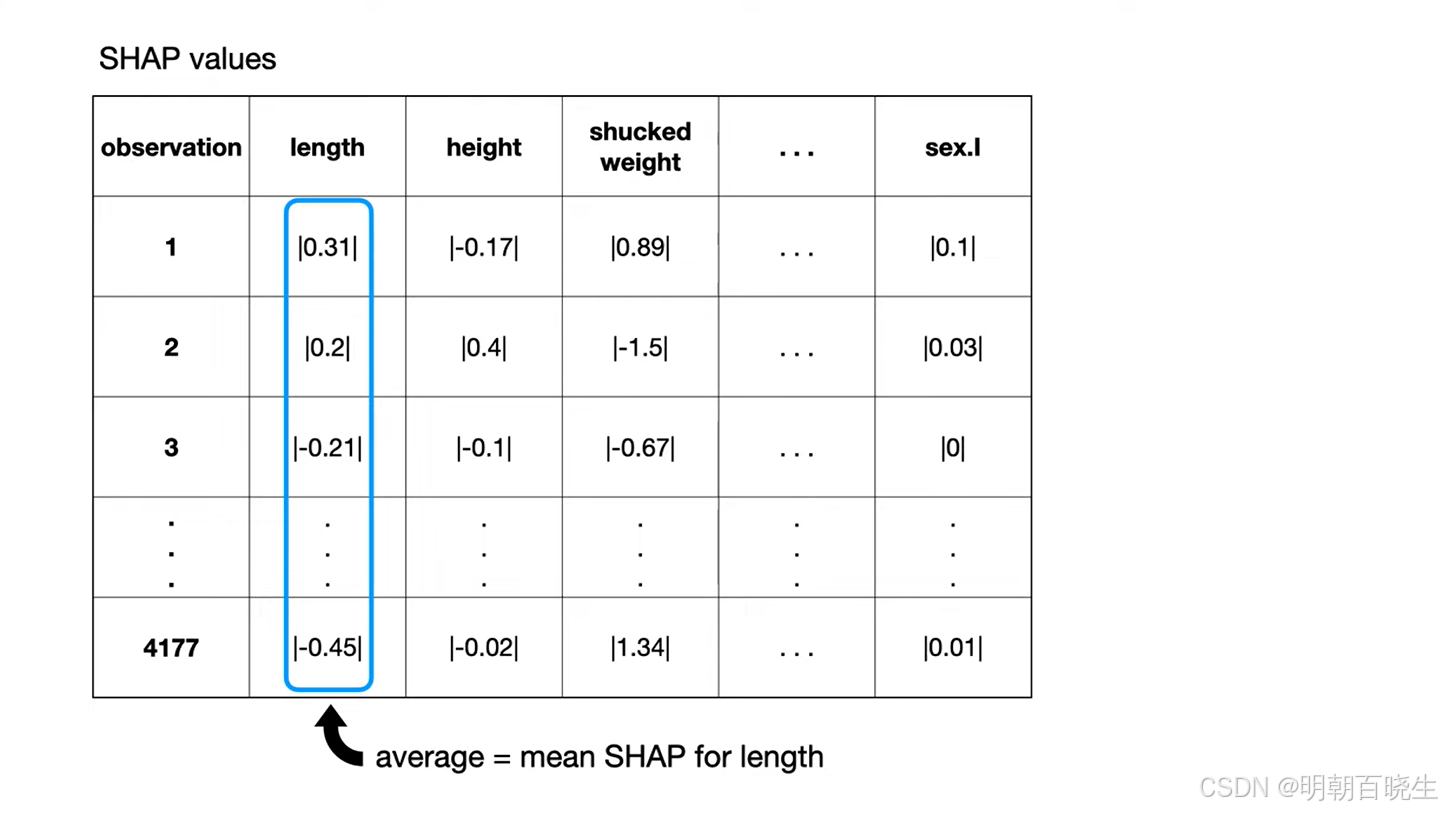
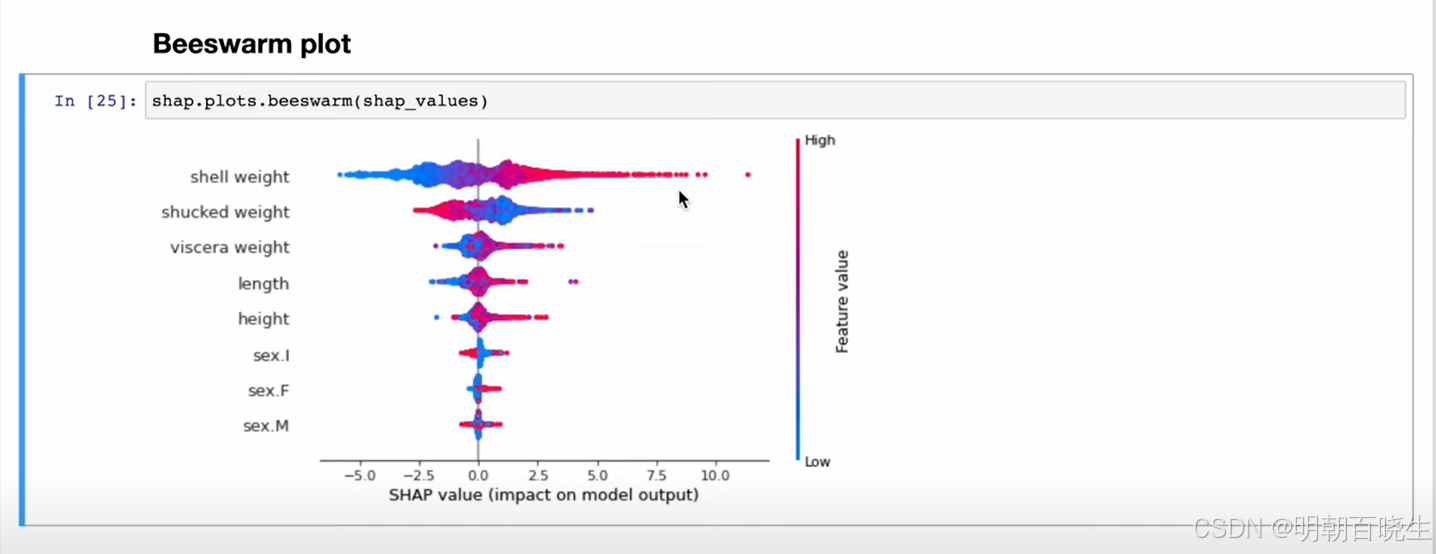
四 SHAP 机器学习中计算方式
我们首选有个训练好的模型,假设某个样本输入的特征为
| age | gender | Body mass index | .. |
| 56 | F | 30 | .... |
根据输入的特征我们得到
我们把Gener这个特征设置为一个随机数 得到
则gender等于F 的边际贡献为 ,根据边际贡献可以计算出SHAP值
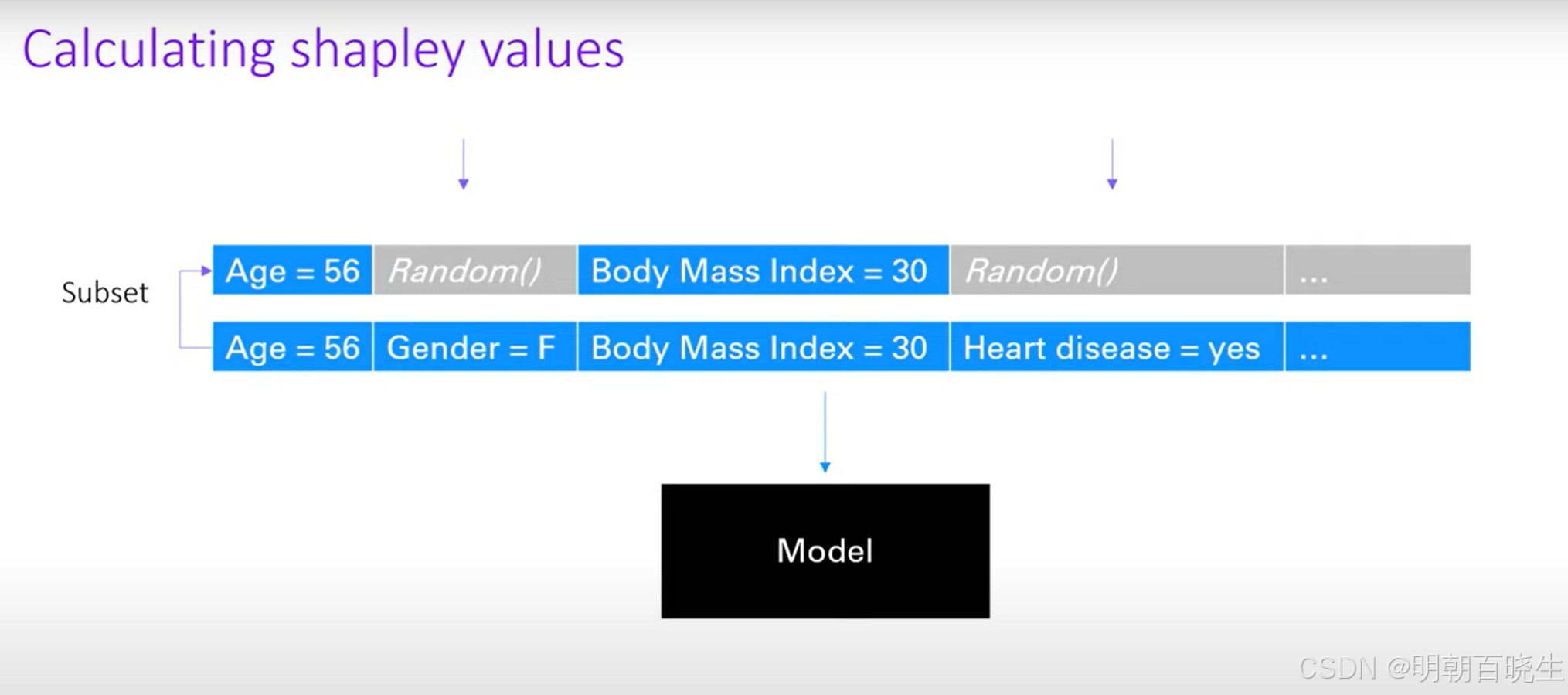
通过上面可以看到,计算shap值过程中,加入有n个特征,每个特征可以有两种取值可能
真实值或者随机数,则一共有个子集

根据模型的不同,shape 也会有不同的初始化方式如下
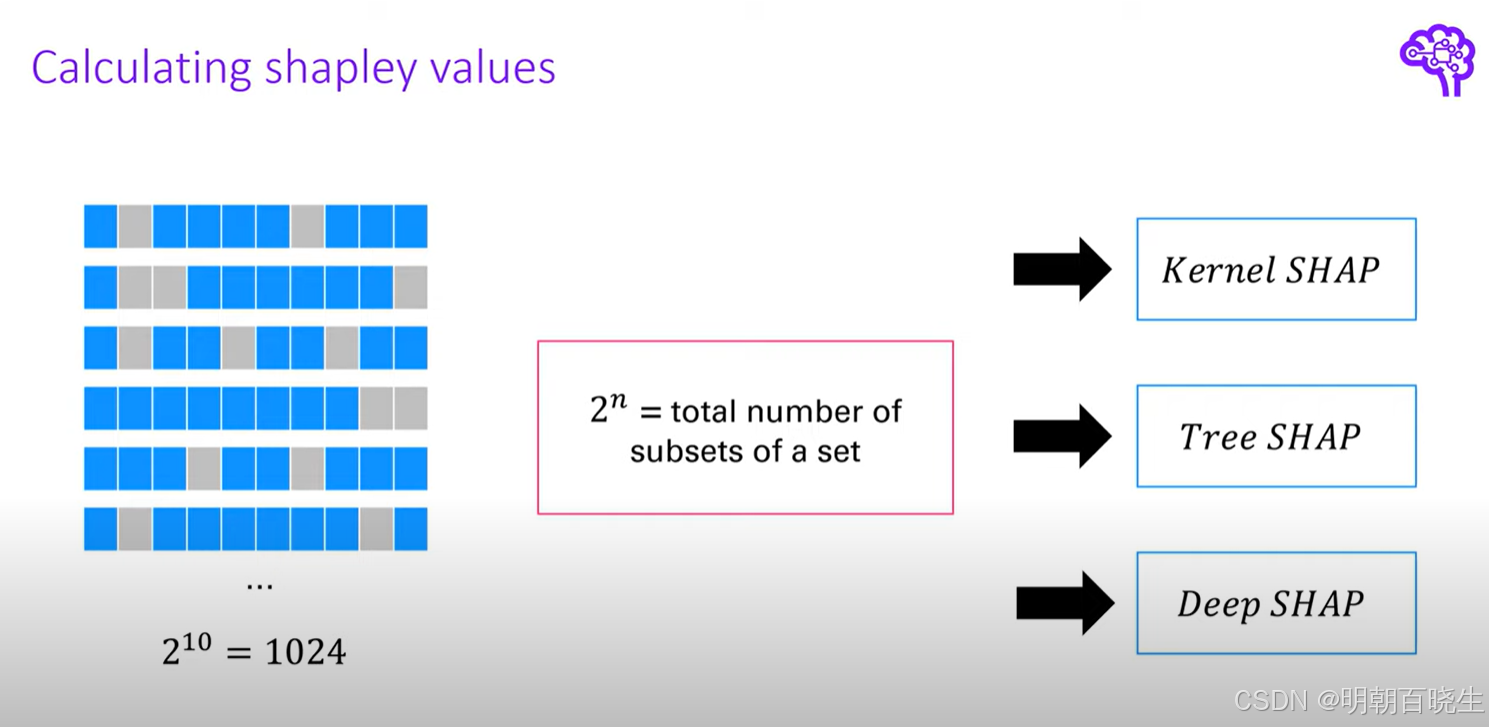
五 SHAP 分类
1. Kernel SHAP
原理:基于经典的Shapley值计算,通过局部加权线性回归(LIME-like)近似Shapley值。
特点:
模型无关:适用于任何机器学习模型(如SVM、随机森林、神经网络等)。
计算成本高:需要大量采样,尤其在特征维度高时效率较低。
适用场景:小型数据集或需要通用解释的场景。
2. Tree SHAP
原理:专为树模型(决策树、随机森林、XGBoost、LightGBM等)优化的算法,利用树结构的递归计算加速。
特点:
高效精确:计算复杂度从指数级降至多项式级(O(TLD2)O(TLD2),其中TT是树的数量,LL是最大叶子数,DD是深度)。
支持交互效应:可计算特征间的交互作用(如
shap_interaction_values)。适用场景:树模型的快速解释(工业界最常用)。
3. Deep SHAP
原理:基于DeepLIFT的改进,用于深度神经网络(DNN)的近似Shapley值计算。
特点:
高效传播:通过反向传播规则近似计算,避免暴力采样。
依赖模型结构:需针对特定网络架构设计。
适用场景:图像、文本等深度学习模型的解释。
4. Linear SHAP
原理:针对线性模型的简化计算,假设特征独立性。
特点:
解析解:直接通过模型系数计算Shapley值,无需采样。
速度快:计算复杂度极低。
适用场景:线性回归、逻辑回归等线性模型。
5. Sampling SHAP
原理:通过蒙特卡洛采样近似Shapley值,减少计算量。
特点:
灵活性高:适用于任何模型,比Kernel SHAP更轻量。
精度依赖采样数:需权衡计算时间和精度。
适用场景:中大型数据集或需要平衡效率与精度的场景。
6. Group SHAP
原理:将多个特征视为一个组(如one-hot编码的类别变量),计算组的联合贡献。
特点:
减少维度灾难:避免高维特征下的计算瓶颈。
更直观解释:适合具有逻辑分组的特征。
适用场景:分类变量或特征分组明显的场景。
7. Approximate SHAP
变体:包括基于梯度的方法(如
GradientSHAP)或其他近似算法,针对特定模型优化。特点:在速度和精度之间折中,可能牺牲理论严谨性。
选择建议
树模型:优先用Tree SHAP(最快且精确)。
深度学习:尝试Deep SHAP或Kernel SHAP。
黑盒模型:Kernel SHAP或Sampling SHAP。
线性模型:Linear SHAP。
参考:
1 SHAP values for beginners | What they mean and their applications【】https://www.youtube.com/watch?v=MQ6fFDwjuco&list=PLqDyyww9y-1SJgMw92x90qPYpHgahDLIK
2 https://www.youtube.com/watch?v=L8_sVRhBDLU&list=PLqDyyww9y-1SJgMw92x90qPYpHgahDLIK&index=2SHAP with Python (Code and Explanations)
2 https://www.youtube.com/watch?v=L8_sVRhBDLU&list=PLqDyyww9y-1SJgMw92x90qPYpHgahDLIK&index=2