乐陵人力资源网站外贸新手怎样用谷歌找客户
目录
简单的神经网络
一、PyTorch的安装
二、准备工作
三、数据的准备
四、模型架构定义
五、模型训练(CPU版本)
1. 定义损失函数和优化器
2. 开始循环训练
3. 可视化结果
六、通俗解释
1. 环境安装(相当于买锅碗瓢盆)
2. 数据准备(洗菜切菜)
3. 模型定义(设计菜谱)
4. 训练过程(炒菜实操)
5. 评估与可视化(考试和总结)
6. 通俗总结
7. 类比问答
简单的神经网络
默认大家已经有一定的神经网络基础,该部分已经在复试班的深度学习部分介绍完毕,如果没有,你需要自行了解下MLP的概念。
你需要知道
- 梯度下降的思想
- 激活函数的作用
- 损失函数的作用
- 优化器
- 神经网络的概念
神经网络由于内部比较灵活,所以封装的比较浅,可以对模型做非常多的改进,而不像机器学习三行代码固定。
一、PyTorch的安装
我们后续完成深度学习项目中,主要使用的包为pytorch,所以需要安装,你需要去配置一个新的环境。
未来在复现具体项目时候,新环境命名最好是python版本_pytorch版本_cuda版本,例如 py3.10_pytorch2.0_cuda12.2 ,因为复杂项目对运行环境有要求,所以需要安装对应版本的包。
我们目前主要不用这么严格,先创建一个命名为DL的新环境即可,也可以沿用之前的环境
conda create -n DL python=3.8
conda env list
conda activate DL
conda install jupyter (如果conda无法安装jupyter就参考环境配置文档的pip安装方法)
pip insatll scikit-learn
然后对着下列教程安装pytorch深度学习主要是简单的并行计算,所以gpu优势更大,简单的计算cpu发挥不出来他的价值,我们之前说过显卡和cpu的区别:
- cpu是1个博士生,能够完成复杂的计算,串行能力强。
- gpu是100个小学生,能够完成简单的计算,人多计算的快。
这里的gpu指的是英伟达的显卡,它支持cuda可以提高并行计算的能力。
如果你是amd的显卡、苹果的电脑,那样就不需要安装cuda了,直接安装pytorch-gpu版本即可。cuda只支持nvidia的显卡。
安装教程
或者去b站随便搜个pytorch安装视频。
- 怕麻烦直接安装cpu版本的pytorch,跑通了用云服务器版本的pytorch-gpu
- gpu的pytorch还需要额外安装cuda cudnn组件
二、准备工作
可以在你电脑的cmd中输入nvidia-smi来查看下显卡信息
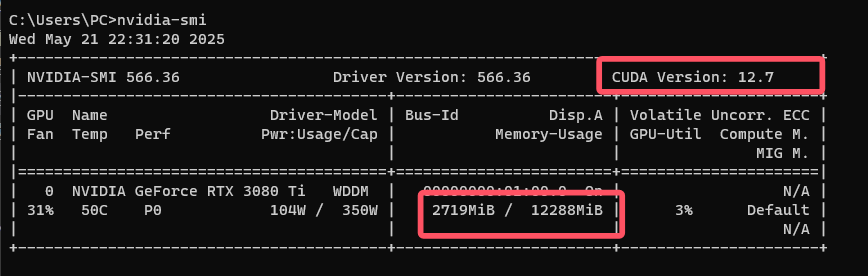
其中最重要的2个信息,分别是:
- 显卡目前驱动下最高支持的cuda版本,12.7
- 显存大小,12288 MiB ÷ 1024 = 12
PS:之所以输入这个命令,可以弹出这些信息,是因为为系统正确安装了 NVIDIA 显卡驱动程序,并且相关路径被添加到了环境变量中。如果你不是英伟达的显卡,自然无法使用这个命令。
import torch
torch.cuda<module 'torch.cuda' from 'd:\\Anaconda\\envs\\yolov5\\lib\\site-packages\\torch\\cuda\\__init__.py'>
import torch# 检查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")
else:print("CUDA不可用。")CUDA可用! 可用的CUDA设备数量: 1 当前使用的CUDA设备索引: 0 当前CUDA设备的名称: NVIDIA GeForce RTX 3080 Ti CUDA版本: 11.1
这里的cuda版本是实际安装的cuda驱动的版本,需要小于显卡所支持的最高版本
上述这段代码,可以以后不断复用,检查是否有pytorch及cuda相关信息,我们今天先用cpu训练,不必在意,有没有cuda不影响。
三、数据的准备
预处理补充:
注意事项:
(1)分类任务中,若标签是整数(如 0/1/2 类别),需转为long类型(对应 PyTorch 的torch.long),否则交叉熵损失函数会报错。
(2)回归任务中,标签需转为float类型(如torch.float32)。
# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)(120, 4) (120,) (30, 4) (30,)
# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)四、模型架构定义
定义一个简单的全连接神经网络模型,包含一个输入层、一个隐藏层和一个输出层。
定义层数+定义前向传播顺序
import torch
import torch.nn as nn
import torch.optim as optimclass MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()其实模型层的写法有很多,relu也可以不写,在后面前向传播的时候计算下即可,因为relu其实不算一个层,只是个计算而已。
# def forward(self,x): #前向传播# x=torch.relu(self.fc1(x)) #激活函数# x=self.fc2(x) #输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy# return x五、模型训练(CPU版本)
1. 定义损失函数和优化器
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)2. 开始循环训练
实际上在训练的时候,可以同时观察每个epoch训练完后测试集的表现:测试集的loss和准确度
# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')输出结果:
Epoch [100/20000], Loss: 1.0730
Epoch [200/20000], Loss: 1.0258
Epoch [300/20000], Loss: 0.9757
Epoch [400/20000], Loss: 0.9200
Epoch [500/20000], Loss: 0.8577
Epoch [600/20000], Loss: 0.7908
Epoch [700/20000], Loss: 0.7247
Epoch [800/20000], Loss: 0.6639
Epoch [900/20000], Loss: 0.6109
Epoch [1000/20000], Loss: 0.5661
Epoch [1100/20000], Loss: 0.5285
Epoch [1200/20000], Loss: 0.4967
Epoch [1300/20000], Loss: 0.4695
Epoch [1400/20000], Loss: 0.4456
Epoch [1500/20000], Loss: 0.4244
Epoch [1600/20000], Loss: 0.4052
Epoch [1700/20000], Loss: 0.3877
Epoch [1800/20000], Loss: 0.3715
Epoch [1900/20000], Loss: 0.3564
Epoch [2000/20000], Loss: 0.3423
Epoch [2100/20000], Loss: 0.3290
Epoch [2200/20000], Loss: 0.3165
Epoch [2300/20000], Loss: 0.3046
Epoch [2400/20000], Loss: 0.2935
Epoch [2500/20000], Loss: 0.2829
Epoch [2600/20000], Loss: 0.2729
Epoch [2700/20000], Loss: 0.2635
Epoch [2800/20000], Loss: 0.2545
Epoch [2900/20000], Loss: 0.2461
Epoch [3000/20000], Loss: 0.2381
Epoch [3100/20000], Loss: 0.2306
Epoch [3200/20000], Loss: 0.2235
Epoch [3300/20000], Loss: 0.2168
Epoch [3400/20000], Loss: 0.2104
Epoch [3500/20000], Loss: 0.2044
Epoch [3600/20000], Loss: 0.1987
Epoch [3700/20000], Loss: 0.1933
Epoch [3800/20000], Loss: 0.1882
Epoch [3900/20000], Loss: 0.1833
Epoch [4000/20000], Loss: 0.1787
Epoch [4100/20000], Loss: 0.1744
Epoch [4200/20000], Loss: 0.1702
Epoch [4300/20000], Loss: 0.1663
Epoch [4400/20000], Loss: 0.1625
Epoch [4500/20000], Loss: 0.1590
Epoch [4600/20000], Loss: 0.1556
Epoch [4700/20000], Loss: 0.1523
Epoch [4800/20000], Loss: 0.1492
Epoch [4900/20000], Loss: 0.1463
Epoch [5000/20000], Loss: 0.1435
Epoch [5100/20000], Loss: 0.1408
Epoch [5200/20000], Loss: 0.1382
Epoch [5300/20000], Loss: 0.1358
Epoch [5400/20000], Loss: 0.1334
Epoch [5500/20000], Loss: 0.1312
Epoch [5600/20000], Loss: 0.1290
Epoch [5700/20000], Loss: 0.1269
Epoch [5800/20000], Loss: 0.1249
Epoch [5900/20000], Loss: 0.1230
Epoch [6000/20000], Loss: 0.1212
Epoch [6100/20000], Loss: 0.1194
Epoch [6200/20000], Loss: 0.1177
Epoch [6300/20000], Loss: 0.1161
Epoch [6400/20000], Loss: 0.1145
Epoch [6500/20000], Loss: 0.1130
Epoch [6600/20000], Loss: 0.1116
Epoch [6700/20000], Loss: 0.1102
Epoch [6800/20000], Loss: 0.1088
Epoch [6900/20000], Loss: 0.1075
Epoch [7000/20000], Loss: 0.1062
Epoch [7100/20000], Loss: 0.1050
Epoch [7200/20000], Loss: 0.1038
Epoch [7300/20000], Loss: 0.1027
Epoch [7400/20000], Loss: 0.1016
Epoch [7500/20000], Loss: 0.1005
Epoch [7600/20000], Loss: 0.0995
Epoch [7700/20000], Loss: 0.0985
Epoch [7800/20000], Loss: 0.0975
Epoch [7900/20000], Loss: 0.0966
Epoch [8000/20000], Loss: 0.0957
Epoch [8100/20000], Loss: 0.0948
Epoch [8200/20000], Loss: 0.0940
Epoch [8300/20000], Loss: 0.0932
Epoch [8400/20000], Loss: 0.0924
Epoch [8500/20000], Loss: 0.0916
Epoch [8600/20000], Loss: 0.0908
Epoch [8700/20000], Loss: 0.0901
Epoch [8800/20000], Loss: 0.0894
Epoch [8900/20000], Loss: 0.0887
Epoch [9000/20000], Loss: 0.0880
Epoch [9100/20000], Loss: 0.0874
Epoch [9200/20000], Loss: 0.0867
Epoch [9300/20000], Loss: 0.0861
Epoch [9400/20000], Loss: 0.0855
Epoch [9500/20000], Loss: 0.0849
Epoch [9600/20000], Loss: 0.0844
Epoch [9700/20000], Loss: 0.0838
Epoch [9800/20000], Loss: 0.0833
Epoch [9900/20000], Loss: 0.0827
Epoch [10000/20000], Loss: 0.0822
Epoch [10100/20000], Loss: 0.0817
Epoch [10200/20000], Loss: 0.0812
Epoch [10300/20000], Loss: 0.0808
Epoch [10400/20000], Loss: 0.0803
Epoch [10500/20000], Loss: 0.0798
Epoch [10600/20000], Loss: 0.0794
Epoch [10700/20000], Loss: 0.0790
Epoch [10800/20000], Loss: 0.0785
Epoch [10900/20000], Loss: 0.0781
Epoch [11000/20000], Loss: 0.0777
Epoch [11100/20000], Loss: 0.0773
Epoch [11200/20000], Loss: 0.0769
Epoch [11300/20000], Loss: 0.0766
Epoch [11400/20000], Loss: 0.0762
Epoch [11500/20000], Loss: 0.0758
Epoch [11600/20000], Loss: 0.0755
Epoch [11700/20000], Loss: 0.0751
Epoch [11800/20000], Loss: 0.0748
Epoch [11900/20000], Loss: 0.0745
Epoch [12000/20000], Loss: 0.0741
Epoch [12100/20000], Loss: 0.0738
Epoch [12200/20000], Loss: 0.0735
Epoch [12300/20000], Loss: 0.0732
Epoch [12400/20000], Loss: 0.0729
Epoch [12500/20000], Loss: 0.0726
Epoch [12600/20000], Loss: 0.0723
Epoch [12700/20000], Loss: 0.0721
Epoch [12800/20000], Loss: 0.0718
Epoch [12900/20000], Loss: 0.0715
Epoch [13000/20000], Loss: 0.0712
Epoch [13100/20000], Loss: 0.0710
Epoch [13200/20000], Loss: 0.0707
Epoch [13300/20000], Loss: 0.0705
Epoch [13400/20000], Loss: 0.0702
Epoch [13500/20000], Loss: 0.0700
Epoch [13600/20000], Loss: 0.0698
Epoch [13700/20000], Loss: 0.0695
Epoch [13800/20000], Loss: 0.0693
Epoch [13900/20000], Loss: 0.0691
Epoch [14000/20000], Loss: 0.0688
Epoch [14100/20000], Loss: 0.0686
Epoch [14200/20000], Loss: 0.0684
Epoch [14300/20000], Loss: 0.0682
Epoch [14400/20000], Loss: 0.0680
Epoch [14500/20000], Loss: 0.0678
Epoch [14600/20000], Loss: 0.0676
Epoch [14700/20000], Loss: 0.0674
Epoch [14800/20000], Loss: 0.0672
Epoch [14900/20000], Loss: 0.0670
Epoch [15000/20000], Loss: 0.0668
Epoch [15100/20000], Loss: 0.0667
Epoch [15200/20000], Loss: 0.0665
Epoch [15300/20000], Loss: 0.0663
Epoch [15400/20000], Loss: 0.0661
Epoch [15500/20000], Loss: 0.0659
Epoch [15600/20000], Loss: 0.0658
Epoch [15700/20000], Loss: 0.0656
Epoch [15800/20000], Loss: 0.0654
Epoch [15900/20000], Loss: 0.0653
Epoch [16000/20000], Loss: 0.0651
Epoch [16100/20000], Loss: 0.0650
Epoch [16200/20000], Loss: 0.0648
Epoch [16300/20000], Loss: 0.0647
Epoch [16400/20000], Loss: 0.0645
Epoch [16500/20000], Loss: 0.0644
Epoch [16600/20000], Loss: 0.0642
Epoch [16700/20000], Loss: 0.0641
Epoch [16800/20000], Loss: 0.0639
Epoch [16900/20000], Loss: 0.0638
Epoch [17000/20000], Loss: 0.0637
Epoch [17100/20000], Loss: 0.0635
Epoch [17200/20000], Loss: 0.0634
Epoch [17300/20000], Loss: 0.0633
Epoch [17400/20000], Loss: 0.0631
Epoch [17500/20000], Loss: 0.0630
Epoch [17600/20000], Loss: 0.0629
Epoch [17700/20000], Loss: 0.0627
Epoch [17800/20000], Loss: 0.0626
Epoch [17900/20000], Loss: 0.0625
Epoch [18000/20000], Loss: 0.0624
Epoch [18100/20000], Loss: 0.0623
Epoch [18200/20000], Loss: 0.0621
Epoch [18300/20000], Loss: 0.0620
Epoch [18400/20000], Loss: 0.0619
Epoch [18500/20000], Loss: 0.0618
Epoch [18600/20000], Loss: 0.0617
Epoch [18700/20000], Loss: 0.0616
Epoch [18800/20000], Loss: 0.0615
Epoch [18900/20000], Loss: 0.0614
Epoch [19000/20000], Loss: 0.0613
Epoch [19100/20000], Loss: 0.0612
Epoch [19200/20000], Loss: 0.0610
Epoch [19300/20000], Loss: 0.0609
Epoch [19400/20000], Loss: 0.0608
Epoch [19500/20000], Loss: 0.0607
Epoch [19600/20000], Loss: 0.0606
Epoch [19700/20000], Loss: 0.0605
Epoch [19800/20000], Loss: 0.0605
Epoch [19900/20000], Loss: 0.0604
Epoch [20000/20000], Loss: 0.0603如果你重新运行上面这段训练循环,模型参数、优化器状态和梯度会继续保留,导致训练结果叠加,模型参数和优化器状态(如动量、学习率等)不会被重置。这会导致训练从之前的状态继续,而不是从头开始
3. 可视化结果
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()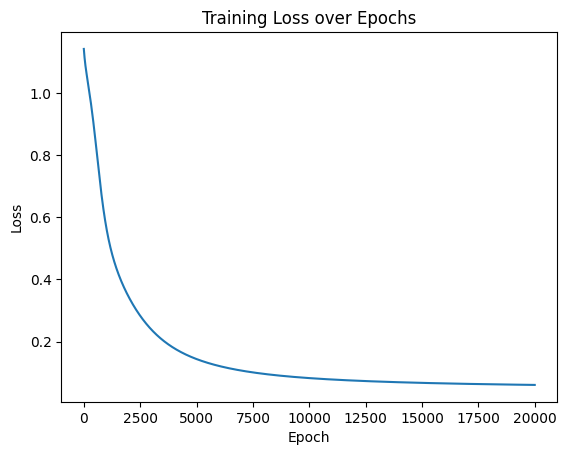
六、通俗解释
1. 环境安装(相当于买锅碗瓢盆)
- PyTorch:就像买了一套厨房工具,用来“炒菜”(训练模型)。
- CUDA:如果电脑有NVIDIA显卡(比如游戏本),可以加速“炒菜”速度,相当于用高压锅。
- 检查显卡:打开电脑的“工具箱”(命令行),输入
nvidia-smi,看看有没有“高压锅”能用。
2. 数据准备(洗菜切菜)
- 鸢尾花数据集:就像你有三种不同颜色的花(Setosa、Versicolor、Virginica),每朵花有四个特征(花瓣长度、宽度等)。
- 数据分割:把花分成两堆,一堆用来“学做菜”(训练集),另一堆用来“考试”(测试集)。
- 归一化:把花的特征数据“调音量”,比如把花瓣长度从0-3cm变成0-1的比例,避免某些特征太大影响模型。
3. 模型定义(设计菜谱)
- MLP模型:就是一个“做菜流程”,比如:
- 第一层(洗菜+切菜):输入4个特征(花瓣、萼片数据),经过10个“小帮手”(神经元)处理。
- 激活函数(ReLU):像“过滤器”,只保留重要的信息(比如过滤掉不新鲜的花)。
- 第二层(炒菜):把处理后的信息交给3个“大厨”(神经元),输出三个概率(预测是哪种花)。
# 代码比喻:定义菜谱
class MLP(nn.Module):def __init__(self):super().__init__()self.layer1 = nn.Linear(4, 10) # 输入4个特征,输出10个中间结果self.layer2 = nn.Linear(10, 3) # 输入10个中间结果,输出3种花的概率4. 训练过程(炒菜实操)
(1)损失函数(老师的评分)
- 交叉熵损失:老师会根据你的预测打分,比如你猜是Setosa(概率0.8),但实际是Versicolor,老师会扣分。
(2)优化器(调整火候)
- SGD(手动翻炒):每次根据老师评分调整火候(学习率),比如火候太大会烧焦(参数更新太大),太小炒不熟(收敛慢)。
- Adam(自动翻炒):更智能的火候调整,适合新手。
(3)训练循环(重复炒菜)
- 前向传播:把菜放进锅里炒(输入数据经过模型)。
- 反向传播:根据老师评分,分析哪里炒糊了(计算梯度)。
- 参数更新:调整盐、油量(模型参数),让下次炒菜更好吃。
# 代码比喻:炒菜过程
for epoch in range(20000):outputs = model(X_train) # 把菜放进锅里炒loss = criterion(outputs, y_train) # 老师打分optimizer.zero_grad() # 清空锅里的油(梯度清零)loss.backward() # 分析为什么难吃(反向传播)optimizer.step() # 调整火候(更新参数)5. 评估与可视化(考试和总结)
- 测试集:用没炒过的菜(测试集)考验模型,看能对几道题(准确率)。
- 损失曲线:画一张“扣分趋势图”,如果扣分越来越少,说明越炒越好。
6. 通俗总结
- 神经网络:就是一个“自动炒菜机器人”,通过不断试错(训练),学会根据食材特征(花瓣长度)判断菜品类型(花的种类)。
- 关键点:
- 数据要干净(归一化):就像洗菜要洗干净。
- 模型要设计合理:就像菜谱步骤不能乱。
- 训练要有耐心:炒菜要反复调整火候。
7. 类比问答
-
Q:为什么需要激活函数?
A:防止模型变成“只会背答案的笨学生”,比如不管输入什么,都输出同样的结果。激活函数让模型学会“思考”(引入非线性)。 -
Q:为什么用GPU?
A:GPU就像有100个厨师同时炒菜,速度飞快。CPU只有一个厨师,适合慢慢做精致菜品(简单计算)。 -
Q:为什么标签要是Long类型?
A:因为模型需要明确知道“正确答案是数字0、1、2”,而不是浮点数(比如0.0、1.0)。